儂乕儉
亜
儕儗乕僔儑僫儖丒僨乕僞儀乕僗偺悽奅
亜
僙儖僐丒僙儗僋僔儑儞
亜
僥乕僽儖偵億儕儌儖僼傿僘儉偼昁梫偐
(DBAzine (2005/09/08), "
One True Lookup Table
")
僫僀僗傾僀僨傾丠
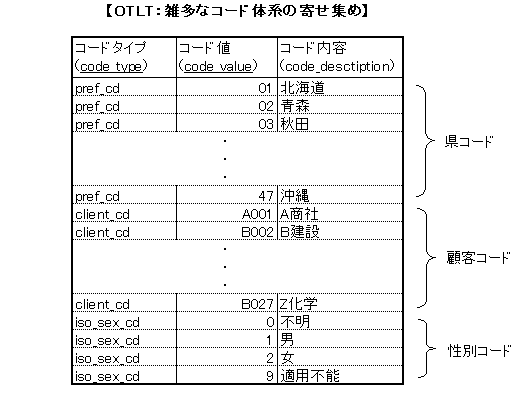
丂奆偝傫傕丄擔乆偺嬈柋偱怓乆側僐乕僪傪巊偭偰偄傞偲巚偄傑偡丅搒摴晎導僐乕僪丄屭媞僐乕僪丄惈暿僐乕僪丄幘昦僐乕僪側偳丄僥乕僽儖偵偼怓乆側庬椶偺僐乕僪楍偑娷傑傟偰偄傞偱偟傚偆丅偦偟偰僐乕僪傪埖偆嵺丄廳梫側懚嵼偲側傞偺偑乽儅僗僞乿僥乕僽儖偱偡丅偮傑傝丄僐乕僪偺慡偰偺廤崌乮導僐乕僪側傜47庬椶乯傪曐帩偟偰偍偔僥乕僽儖偱偡丅摑寁昞傪嶌惉偡傞偲偒側偳丄昞懁丒昞摢偑屌掕揑側寢壥偑梸偟偄偲偒偵偼丄偙偺儅僗僞僥乕僽儖傪庡偵偟偰僨乕僞僥乕僽儖偲奜晹寢崌偡傞偲偄偆曽朄偑堦斒揑偱偡丅僨乕僞僥乕僽儖偺傒偩偲丄偨傑偨傑杒奀摴偺僨乕僞偑僥乕僽儖偵娷傑傟偰偄側偄応崌偵偼丄昞懁偑1峴寚偗偰偟傑偭偰婐偟偔偁傝傑偣傫丅
丂偦偆偡傞偲丄偙偺儅僗僞僥乕僽儖偲偄偆偺偼丄婎杮揑偵僐乕僪懱宯偺悢偩偗昁梫偲偄偆偙偲偵側傝傑偡丅導僐乕僪儅僗僞丄屭媞儅僗僞丄幘昦儅僗僞ゥゥゥ摍乆丅儅僗僞偺悢偑憹偊傞偙偲帺懱偑懄嵗偵埆偄丄偲偄偆偙偲偵偼側傜側偄偺偱偡偑丄偟偐偟戝偟偰峴悢偺側偄彫婯柾僥乕僽儖偑偳偝偳偝憹偊傞偺偼丄僄儞僕僯傾偲偟偰偺旤堄幆偵堷偭偐偐傞偲偙傠偑偁傞偺傕帠幚丅偦傟側傜偄偭偦偺偙偲丄偙偄偮傜慡晹傑偲傔偰堦偮偺僥乕僽儖偵曻傝崬傫偱偟傑偭偨曽偑偄偄傫偠傖側偄両丠 楍傕帡偨傝傛偭偨傝偩偟丄梡搑傕摨偠偩偟丄僥乕僽儖偺悢傕尭偭偰 ER恾傕偡偭偒傝偝傢傗偐両 偆傫丄偙傟偱峴偙偆両
丂偙偆偟偰嶌傜傟傞偙偲偵側傞偺偑丄僙儖僐偺尵偆乽One True Lookup Table乿 乗乗 姼偊偰栿偡側傜乽
扨堦嶲徠僥乕僽儖
乿偲偱傕側傞偱偟傚偆偐 乗乗 棯偟偰 OTLT丅嬶懱揑偵偼壓恾偺傛偆側撪梕偵側傝傑偡丅
丂僙儖僐偺庤慜丄戝偒側惡偱偼尵偊傑偣傫偑丄
巹傕偙偺 OTLT 傪巊偭偨偙偲偑偁傝傑偡丅
偲偄偭偰傕丄尵偄栿偟偰偍偔偲丄巹偑愝寁偟偨偺偱偼側偔丄僾儘僕僃僋僩偵擖偭偨偲偒偵偼婛偵 OTLT 偑懚嵼偟偰偄偰丄乽偙傟巊偭偰乿偲尵傢傟偨偺偱偡偗偳丅
丂偙偺僥乕僽儖傪巊偭偰丄搒摴晎導暿偺恖岥傪廤寁偟傛偆偲偡傞 SQL 偼丄椺偊偽壓偺傛偆偵側傝傑偡丅
丂丂SELECT MASTER.pref_cd,
丂丂丂丂丂 丂丂丂DATA.population
丂丂丂 FROM丂 (SELECT pref_cd, SUM(population) AS population
丂丂丂丂丂丂丂丂丂丂FROM DataTable
丂丂丂丂丂丂丂丂丂GROUP BY pref_cd) DATA
RIGHT OUTER JOIN
丂丂丂丂丂丂丂丂 (SELECT code_value
丂丂丂丂丂丂丂丂丂丂FROM LookUp
丂丂丂丂丂丂丂丂丂 WHERE code_type = 'pref_cd' )
MASTER
丂丂--僀儞儔僀儞丒價儏乕偱搒摴晎導儅僗僞傪嶌傞
丂丂丂丂丂ON丂DATA.pref_cd = MASTER.pref_cd ;
FROM嬪偺僀儞儔僀儞丒價儏乕乮MASTER乯偱搒摴晎導儅僗僞傪嶌傝丄偦傟傪庡偵奜晹寢崌偟偰偄傑偡丅偙偺價儏乕偑丄応崌偵傛偭偰惈暿儅僗僞偵側偭偨傝幘昦儅僗僞偵側偭偨傝丄幍曄壔偡傞傢偗偱偡丅
棙揰偲寚揰
丂巹偑 OTLT 傪巊偭偨嵟弶偺姶憐偼丄乽寢峔曋棙側傕偺偩乿偲偄偆峬掕揑側傕偺偱偟偨丅摿偵僔僗僥儉偺婯柾偑偁傑傝戝偒偔側偄応崌偼丄僥乕僽儖偺僒僀僘傕偦傟傎偳戝偒偔側傜偢丄娷傑傟傞僐乕僪懱宯偺娗棟傕堦妵偱峴側偊傑偡丅偟偐偟僙儖僐偼偙偺婰帠偱丄OTLT 偺巊梡偵嫮偄寈忇傪柭傜偟偰偄傑偡丅杮峞偺庡娽偼丄斵偑偙偺庤朄傪斸敾偡傞棟桼傪棟夝偡傞偙偲偵偁傞偺偱偡偑丄偦偺慜偵丄傑偢偼偙偺庤朄偺棙揰偺曽傪惍棟偟傑偟傚偆丅僙儖僐偼乽弶怱幰偵偼恖婥偑偁傞傫偩偗偳偹乿偲僠僋儕偲巋偡偩偗偱丄棙揰偼嬶懱揑偵偼嫇偘偰偄傑偣傫丅偟偐偟丄弶怱幰偩偗偵偣傛丄恖婥偑偁傞偺側傜丄偦偙偵偼恖婥偑偁傞偩偗偺棟桼傕摨帪偵偁傞偲偄偆偙偲偱偡偐傜丄堦墳偦傟傕嫇偘偰偍偐側偄偲僼僃傾偠傖偁傝傑偣傫丅
丂巹偑巚偆偵丄OTLT 偺帩偮棙揰偼埲壓偺捠傝偱偡丅
儅僗僞僥乕僽儖偺悢偑尭傞偺偱丄ER恾偑僔儞僾儖偵側傝丄棟夝偟傗偡偄丅
僐乕僪専嶕偺SQL傪嫟捠壔偱偒傞丅
暋悢偺嬈柋偱巊梡偡傞僐乕僪廤崌傪堦売強偱娗棟偱偒傞偺偱丄曐庣丒娗棟偑梕堈偵側傞丅
丂摿偵丄2.斣偲3.斣偼丄偙偺愝寁偺戝偒側棙揰偩偲幚姶偟傑偟偨丅嫟捠壔偵傛偭偰愝寁傪扨弮壔偱偒傞偺偱偡偐傜丄偙傟偑懡偔偺僄儞僕僯傾偵枺椡揑側庤朄偵塮偭偰傕晄巚媍偱偼偁傝傑偣傫丅
丂偟偐偟丄僙儖僐偑巜揈偡傞傛偆偵丄偙偺曽朄偵偼幚梡柺偲棟榑柺偺椉柺偱丄柍帇偱偒側偄寚揰傕書偊偰偄傑偡丅斵偑巜揈偡傞寚揰偼埲壓偺捠傝偱偡丅
僐乕僪偺惍崌惈傪曐偮偨傔偵丄僥乕僽儖掕媊偺 DDL 偵 CASE幃傪梡偄偨挿戝側 CHECK 惂栺傪彂偐偹偽側傜側偄丅
偦傟偧傟偺楍傪丄DBMS 偑嫋梕偡傞嵟戝偺 VARCHAR乮応崌偵傛偭偰偼 NVARCHAR 乯偱愰尵偡傞昁梫偑偁傞丅偦偺寢壥丄娫堘偭偨僨乕僞傪奿擺偡傞婋尟偑憹偊傞丅
暋悢偺儅僗僞傪巊偆応崌偵斾傋偰堦僥乕僽儖偺峴悢偑懡偔側傝丄専嶕偺僷僼僅乕儅儞僗偑埆壔偡傞丅乽僐乕僪抣乿楍偺寢崌帪偵宆曄姺偑敪惗偡傞偲側偍偝傜丅
SQL 撪偱僐乕僪僞僀僾傗僐乕僪抣傪娫堘偊偰巜掕偟偰傕僄儔乕偵側傜偢丄娫堘偭偨寢壥偑曉偝傟傞丅偦偺偨傔娫堘偄偵婥晅偒偵偔偄
僥乕僽儖偼柍娭學側梫慺偺婑偣廤傔偱偼側偔丄摨堦庬椶偺暔偺廤崌偱偁傞偲偄偆儌僨儕儞僌偺尨棟偵斀偡傞
丂巹帺恎丄2.斣偺寚揰偺偨傔偵寵側宱尡傪偟偨偙偲偑偁傝傑偡丅乽僐乕僪抣乿楍偺僒僀僘偑偨偭偨偺5僶僀僩乮両乯偱愰尵偝傟偰偄偨偨傔丄7僶僀僩偺僐乕僪傪搊榐偱偒側偐偭偨偺偱偡丅偍傑偗偵丄條乆側嬈柋偱嫟捠偵巊偆僥乕僽儖偲偄偆偙偲偑嵭偄偟偰丄楍偺僒僀僘傪奼挘偡傞偙偲傕嫋偝傟偢丄寢嬊丄暿偵偦傟愱梡偺儅僗僞僥乕僽儖傪嶌傞偲偄偆杮枛揮搢側寢壥偵廔傢傝傑偟偨丅偣傔偰嵟弶偵10僶僀僩偖傜偄偱愰尵偟偰偍偄偰偔傟傟偽ゥゥゥ丅崱偱傕擺摼偺偄偐側偄愝寁偲偟偰摢偐傜棧傟側偄帠椺偱偡丅乮偐偲偄偭偰丄僒僀僘傪憹傗偣偽憹傗偡傎偳丄僙儖僐偺尵偆傛偆偵娫堘偭偨僨乕僞偑搊榐偝傟傞婋尟傕憹偊傞偺偱偡偑丅乯
丂偦偺懠偺寚揰偵偮偄偰偼丄1丄3斣偼丄乽偦偺捠傝偩偗偳丄抳柦揑側傕偺偲偼巚偊側偄乿偲偄偆儗儀儖偱偡丅CHECK 惂栺偼妋偐偵暋嶨偵側傝傑偡偑丄搳偘弌偟偨偔側傞傎偳暋嶨夦婏側傕偺偵偼側傝傑偣傫偟丄廋惓偑昁梫側僞僀儈儞僌偼丄怴偟偄僐乕僪懱宯傪搊榐偡傞偲偒偩偗偱偡
[
1
]
丅僷僼僅乕儅儞僗偺栤戣傕丄{ 僐乕僪僞僀僾, 僐乕僪抣 } 偺庡僉乕偺僀儞僨僢僋僗偑巊梡偱偒傟偽丄嬌抂偵埆壔偡傞偙偲偼側偄偱偟傚偆丅偨偩丄偪傚偭偲栵夘側偺偼 4.斣偱偡丅偙傟偼丄奐敪幰偺晄拲堄偑尒偮偗偵偔偄僶僌傪惗傓梫場偲側傞惈幙偺偨傔丄杮摉偵岲傑偟偔偁傝傑偣傫丅
丂偦偟偰丄傕偆堦偮丄僙儖僐偑嫇偘偰偄側偄寚揰傪捛壛偟偰偍偒偨偄偲巚偄傑偡丅偦傟偼
丂丂丂丂丂
悽戙娗棟偺昁梫側僐乕僪懱宯傪 OTLT 偱娗棟偡傞偺偼崪偑愜傟傞丅
丂偲偄偆偙偲偱偡丅導僐乕僪傗惈暿偺傛偆偵敿塱媣揑偵晄曄偺懱宯側傜 OTLT 偱堦妵娗棟偡傞儊儕僢僩偼戝偒偄偺偱偡偑丄屭媞僐乕僪傗幘昦僐乕僪偺傛偆偵帪娫偲偲傕偵僐乕僪廤崌偑曄壔偡傞傛偆側懱宯偺応崌丄娗棟偑擄偟偔側傝傑偡丅乽擭寧乿楍傪捛壛偡傞偙偲偵側傞偱偟傚偆偑丄帪娫曄壔偟側偄懱宯偲偺偛偭偨幭僥乕僽儖偵偡傞偺偼彮偟柧椖偝傪寚偒傑偡偟丄専嶕 SQL 傪嫟捠壔偡傞曽朄傕岺晇偑梫傝傑偡丅偦傟偖傜偄側傜丄帪娫曄壔偡傞懱宯偵偮偄偰偼撈棫偺儅僗僞僥乕僽儖傪嶌偭偨曽偑椙偄傛偆偵巚偊傑偡偑丄偦傟偱偼僐乕僪偺堦妵娗棟偲偄偆丄OTLT 偺偦傕偦傕偺栚昗偑曵傟傞偙偲偵側傝傑偡丅
丂傑偨丄5.斣偵娭楢偟偰丄僙儖僐偼 OTLT 偺敪憐偺尮偵偮偄偰柺敀偄姩孞傝傪偟偰偄傑偡丅偙傟偑曇傒弌偝傟偨攚宨偵偼丄僆僽僕僃僋僩巜岦揑側
億儕儌儖僼傿僘儉
偺敪憐偑偁傞偺偱偼側偄偐丄偲偄偆偺偱偡丅妋偐偵丄OTLT 偲偼梫偡傞偵丄堦偮偺僥乕僽儖偵丄応崌応崌偵墳偠偰堎側傞僥乕僽儖偱偁傞偐偺傛偆偵怳晳傢偣傞曽朄偱偡偐傜丄偦偺堄枴偱僥乕僽儖傪巊偭偨億儕儌儖僼傿僘儉偲尵偊側偔傕偁傝傑偣傫丅側偐側偐戩敳側帇揰偱偡偑丄乽僥乕僽儖偼僋儔僗偱偼側偄偺偵ゥゥゥ乿偲丄杮恖偼傏傗偒愡偱偡丅僙儖僐偵尷傜偢丄儕儗乕僔儑僫儖丒僨乕僞儀乕僗奅偺榑幰偺懡偔偼丄僥乕僽儖愝寁偵僆僽僕僃僋僩巜岦揑側敪憐傪帩偪崬傑傟傞偙偲傪寵偄傑偡偟丄幚嵺偵懡偔偺応崌丄旕岠棪揑偱偡丅
丂偱傕偒偭偲 OTLT 傪巊偭偰偄傞恖偺戝敿偼丄偦偙傑偱怺偔峫偊偰偄傞傢偗偱偼側偔丄乽嫟捠壔偱偒傞晹暘偼嫟捠壔偟偨偄乿偲偄偆慺杙側敪憐偱傗偭偰偄傞偩偗偱偟傚偆丅偟偐偟丄偙偆偄偆晽偵尰徾傪尒傞帇揰傪曄偊偰丄偦偺墱偵愽傓尨棟傑偱庢傝弌偟偰尒偣偰偔傟傞偺偑丄僙儖僐傪撉傓戠岉枴偺堦偮偱偡丅
傑偲傔
丂巹偼丄OTLT 傪愨懳偵巊偆傋偒偱偼側偄丄偲偼巚偄傑偣傫丅柧妋側堄恾偺偁傞愝寁曽恓偱偡偟丄幚尰曽朄傕偄偨偭偰僔儞僾儖丄偟偐傕嫕庴偱偒傞儊儕僢僩偼丄帪偲応崌傪慖傋偽偐側傝戝偒偄偐傜偱偡丅偄偮偱傕攏幁偺堦偮妎偊偺傛偆偵偙傟傪巊偆偺偼栤戣偲偟偰傕丄僩儗乕僪僆僼偺寁嶼傪偟偰巊偆暘偵偼嫋偝傟傞偲巚偄傑偡丅偨偩偟丄壖偵 OTLT 傪嵦梡偡傞応崌偱傕丄僙儖僐偑嬯尵傪掓偟偨彅乆偺棟桼偲丄偙傟偑儕儗乕僔儑僫儖丒僨乕僞儀乕僗偺悽奅偺惓摑揑側嫵媊偐傜偼奜傟傞曽朄偩偲偄偆偙偲偼丄棟夝偟偰偍偒傑偟傚偆丅
拹
[1]
CHECK 惂栺側偳晅偗側偗傟偽傛偄偺偱偼側偄偐丄偲偄偆斶偟偄偙偲偼尵傢側偄偱偔偩偝偄丅儅僗僞僥乕僽儖偺僨乕僞偑岆偭偰偄傞偲偄偆偺偼丄僨乕僞僥乕僽儖偺僨乕僞偑岆偭偰偄傞偙偲傛傝傕偢偭偲廳戝側帠懺傪彽偒傑偡丅儅僗僞僥乕僽儖偺僨乕僞偵偼尩枾偵僠僃僢僋傪峴側偆傋偒偱偡丅偟偐傕丄戝検僨乕僞偺 INSERT 傗 DELETE 偑敪惗偡傞僥乕僽儖偱偼側偄偺偱丄CHECK 惂栺偑僷僼僅乕儅儞僗埆壔傪彽偔婋尟傕掅偄偺偱偡偐傜丅
Copyright (C) 儈僢僋
嶌惉擔丗2006/07/17
嵟廔峏怴擔丗2006/07/18
栠傞