ホーム > リレーショナル・データベースの世界 >
セルコ・セレクション >
開始日と終了日をまとめる
(DBMS (1998/04/02), "Tooling Around")
※ただし関係するのは Puzzle コーナーのみ。
多くの会社が、社員の仕事状況を管理するためのツールを使っていると思います。もちろん、個人事業主の方も使っているでしょう。そのツールとしてリレーショナル・データベースを使っている企業があるかどうか、私は知らないのですが、もしそういう用途でテーブルを作るとしたら、一番単純に考えると、次のようになるでしょう。
Timesheets
仕事
(job) | 開始日
(startdate) | 終了日
(enddate) |
|
| J1 | 1998-01-01 | 1998-01-03 |
| J2 | 1998-01-06 | 1998-01-10 |
| J3 | 1998-01-05 | 1998-01-08 |
| J4 | 1998-01-20 | 1998-01-25 |
| J5 | 1998-01-18 | 1998-01-23 |
| J6 | 1998-02-01 | 1998-02-05 |
| J7 | 1998-02-03 | 1998-02-08 |
| J8 | 1998-02-07 | 1998-02-11 |
社員の識別子がありませんが、ある一人の社員についての部分を抜き出したもの、と考えてください。この社員(ジョンとしましょう)、複数の仕事を同時並行で進めつつ、全くヒマな時間も結構多いあたり、なかなか要領のいい人間のようです。
しかしジョンの働きぶりを見た上司はこう考えます。「こいつが遊んでいる時間にも仕事をさせれば、さらに生産性が上がるぞ。ジョンはまだ自分の力を100%発揮していない。」 少なくともシステム業界において、この上司の考えは当てはまりません。プログラマやエンジニアの生産性は、仕事時間に比例するタイプのものではないからです。
しかし上司は、それがジョンのためにもなると確信して、彼が仕事している期間とヒマな期間の割り出しに取り掛かります。おまけにご丁寧に、今月だけでなく、これからもずっと使える方法にしようと、もう一人の部下のプログラマに要求を満たす SQL の作成を命じました。今回の私たちの役回りは、このプログラマです。
テーブルで見ていてもイメージが湧きにくいので、ガントチャートで状況を整理しましょう。
今回 SQL で取得したいのは、一番下の J0 で表した期間を表す開始日と終了日の組み合わせです。 J0 は、ジョンがどんな仕事をしているかはとりあえず不問にして、とにかく彼が仕事をしているか否かだけを考えて線引きしたものです。すなわち、目指す結果はこうです。
startdate enddate
------------- -------------
1998-01-01 1998-01-03
1998-01-05 1998-01-10
1998-01-18 1998-01-25
1998-02-01 1998-02-11
ではまず第一段階です。手始めに、ざっくりした大雑把な集合を作ることから考えましょう。開始日と終了日の一番大きな組み合わせの集合を考えます。馬鹿正直に直積を作ってもいいのですが、少し考えると、開始日が終了日より後になるような組み合わせ(例:1月10日 〜 1月6日)には明らかに意味がないので、これを除外して作ります。次のような SQL になります。
--開始日と終了日の可能な全ての組み合わせを得る
SELECT T1.startdate AS startdate,
T2.enddate AS enddate
FROM Timesheets T1, Timesheets T2
WHERE T1.enddate <= T2.enddate --無意味な組み合わせを排除する
結果:
startdate enddate
------------- -------------
1998-01-01 1998-01-03
1998-01-01 1998-01-08
1998-01-01 1998-01-10
1998-01-01 1998-01-23
1998-01-01 1998-01-25
1998-01-01 1998-02-05
1998-01-01 1998-02-08
1998-01-01 1998-02-11
1998-01-05 1998-01-08
1998-01-05 1998-01-10
1998-01-05 1998-01-23
・
・
・
結果が長いので全部は書き並べませんが、36行選択されます。ここから不要な行を削っていきます。結果を見ると、不要な行は次のような2種類に分類されることが分かります(両方に含まれるものもありますけど)。
- 他の期間とオーバーラップしていて、もっと長い一つの期間にまとめられる。
- 期間の途中にジョンがサボっていた期間が含まれていて、歯抜けになっている。
1番の例としては、例えば「1月5日 〜 1月8日」がそうです。これは、もっと長い「1月5日 〜 1月10日」さえあれば不要です。2番の例としては、「1月3日 〜 1月8日」がそうです。ジョンは 1月4日にサボっているので、期間が連続していません。これらを結果から排除すれば、目指す結果が得られます。
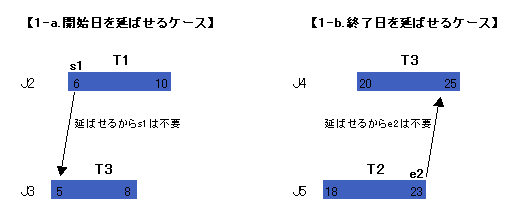
それでは、1番のオーバーラップする期間のうち、最長の期間だけを残す条件を追加しましょう。不要な短い期間は、さらに次の二つの種類に分類できます。
- 1-a. 開始日をもっと前に伸ばせるケース
- 1-b. 終了日をもっと後に伸ばせるケース
これらの条件に該当する期間を除外することで、ジョンがいくつの仕事を同時に掛け持ちしていようとも、一つの期間としてまとめることができます。というわけで、この比較をするために、新しく集合 T3 を追加して作った SQL が次のものです[1]。
--中途半端な開始日と終了日の期間を除外する
SELECT T1.startdate AS startdate,
T2.enddate AS enddate
FROM Timesheets T1, Timesheets T2, Timesheets T3 --T3を追加
WHERE T1.enddate <= T2.enddate
GROUP BY T1.startdate, T2.enddate
HAVING COUNT(CASE
WHEN (T1.startdate > T3.startdate
AND T1.startdate <= T3.enddate) --条件1-a
OR
(T2.enddate >= T3.startdate
AND T2.enddate < T3.enddate) --条件1-b
THEN 1 END) = 0
結果:
startdate enddate
------------- -------------
1998-01-01 1998-01-03
1998-01-01 1998-01-10
1998-01-01 1998-01-25
1998-01-01 1998-02-11
1998-01-05 1998-01-10
1998-01-05 1998-01-25
1998-01-05 1998-02-11
1998-01-18 1998-01-25
1998-01-18 1998-02-11
1998-02-01 1998-02-11
結果は10行。だいぶ答えに近づきました。ご覧のように、もうこの結果には中途半端な開始日や終了日は一つも含まれていません。ちょっとこの SQL について補足しておくと、GROUP BY句を使ったのは、T3 を追加したことで、そのままだと冗長な結果が現れるのを防止するためです。それに伴って、オーバーラップする期間を除外する条件も、WHERE句ではなく HAVING句で書いています。
ところで、この HAVING句を見たとき、CASE式を使うなんて妙な書き方だ、と思った方もいると思います。実はこれ、集合論の特性関数(characteristic function)を忠実に模倣しているからです。特性関数とは、入力項がある集合に含まれるかどうかを調べるための関数で、含まれるなら 1 を、含まれないなら 0 を返すものです。イメージとしては、入荷された商品を眺めて、「これ要るー、これ要らないー」とポイポイ仕分けをする卸業者みたいなものです。今回は、条件 1-a と 1-b に引っかかった期間を集合から除外する役割を果たしています。
さて、それではラストの変更です。歯抜けを含む期間を除外することを考えます。「1月1日 〜 2月11日」なんて期間は、三つもの歯抜けを含んでいます。そりゃ一番外側の開始日と終了日を使えば、重複期間を全部飲み込めますけど、これでは使い物になりません。
歯抜けを除外するのは簡単です。開始日が同じグループに注目して結果を見てもらうと分かるように、要するに終了日が一番小さい期間、つまり一番短い期間を取得すればいいのです。なぜなら、一度歯抜けが出来れば、そこで一つの期間は必ず途切れて、次の期間はまた別の開始日を起点として始まるからです。そしていま、特性関数によって各開始日と終了日は、オーバーラップする期間同士のうち最長になる組み合わせだけが選択されているのですから。というわけで、最終回答はこうです。
--最終回答:歯抜けを含む期間を除外
SELECT startdate,
MIN(enddate) AS enddate
FROM
( SELECT T1.startdate AS startdate,
T2.enddate AS enddate
FROM Timesheets T1, Timesheets T2, Timesheets T3
WHERE T1.enddate <= T2.enddate
GROUP BY T1.startdate, T2.enddate
HAVING COUNT(CASE
WHEN (T1.startdate > T3.startdate AND T1.startdate <= T3.enddate) --条件1-a
OR (T2.enddate >= T3.startdate AND T2.enddate < T3.enddate) --条件1-b
THEN 1 END) = 0 )
GROUP BY startdate;
結果:
startdate enddate
------------- -------------
1998-01-01 1998-01-03
1998-01-05 1998-01-10
1998-01-18 1998-01-25
1998-02-01 1998-02-11
ようやくゴールです。お疲れ様でした。
さっき、特性関数というのは、ある物が集合に含まれるか含まれないかを決定する関数だ、と説明しました。そうすると、特性関数を一つ作るというのは、集合を一つ作るというのとほとんど同じようなものです。特性関数を集合の定義と考えてもよいぐらいです。そのため、特性関数は別名、定義関数(definition function)とも呼ばれます。
集合を作ると言えば、日々私たちが作っている WHERE句の条件だって、もとの集合から別の集合を切り出しているのだから、特性関数と同じ働きをしています。違いといえば、戻り値が 0、1 という整数か、true、false、unknown という真理値か、という点だけです。そんな発想で、さっきのクエリを、特性関数を使わずに、WHERE句で代用して作ったのが、下の SQL です[2]。
--正解その2:HAVING句を使わない
SELECT startdate,
MIN(enddate) AS enddate
FROM
(SELECT T1.startdate,
T2.enddate
FROM Timesheets T1, Timesheets T2
WHERE T1.enddate <= T2.enddate
AND NOT EXISTS (SELECT * FROM Timesheets T3
WHERE (T1.startdate > T3.startdate AND T1.startdate <= T3.enddate) --条件1-a
OR (T2.enddate >= T3.startdate AND T2.enddate < T3.enddate) --条件1-b
)
)
GROUP BY startdate;
特性関数の代わりに、NOT EXISTS述語を使って不要な行を集合から除外しています。これも正解です。
結果が同じで、SQL の複雑さも同程度となると、気になるのがパフォーマンスです。普通、NOT EXISTS述語は非常に高速に動作します。HAVING句で COUNT関数を使うよりも良い場合が多いでしょう。しかし、セルコはこのケースに限っては、COUNT関数を使う方が速いだろうという判断を下しています。ちょっとその理由が私には分からないのですが、もしヒマなとき気が向いたら、双方の実行計画を調べてみてください。
今回のように、最初から求める結果は分かっているのだけど、求める方法が見当らない場合、最初に考えられる最大の集合から出発して、彫刻を作るように徐々に不要な部分を削っていって、最終的に求める形にする、という方法が有効です(彫刻と違って、削りすぎてもまた肉付けできるのが気楽です)。そして削るときに強力な武器になるのが、特性関数と補集合の考え方です。この方法、特に名前が付いているわけではないようなので、とりあえず「彫刻法」とか「削りだし法」とでも呼んでおきましょう。SQL のように集合を扱う言語ではとても力を発揮するので、頭の片隅に入れておいてください。
註
[1]
このように、使いたい集合を好きなだけ簡単に追加できるというのも、SQL の大きな長所です。やりすぎると複雑になって地獄を見ますけど。
[2]
この SQL は、本稿を
リクエストしていただいた明智重蔵氏の
サイトから引用しました。
Copyright (C) ミック
作成日:2006/07/26
最終更新日:2006/07/28