| 1 | HAVING COUNT (DISTINCT col_x) = COUNT (col_x) | col_x の値が一意である。 |
| 2 | HAVING COUNT(*) = COUNT(col_x) | col_x に NULL が存在しない |
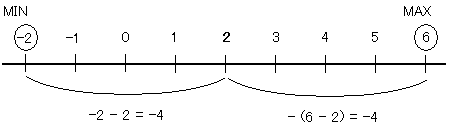
| 3 | HAVING MIN(col_x - 定数) = - MAX(col_x - 定数) | col_x の最大値と最小値が指定した定数から同じ幅の距離にある |
| 4 | HAVING MIN(col_x) = - MAX(col_x) | col_x の最大値と最小値がゼロから同じ距離にある |
| 5 | HAVING MIN(col_x) * MAX(col_x) < 0 | 最大値の符号が正で最小値の符号が負 |
| 6 | HAVING MIN(col_x) * MAX(col_x) = 0 | 最大値と最小値の少なくともどちらかがゼロ |
| 7 | HAVING MIN(col_x) * MAX(col_x) > 0 | 全ての col_x の符号が同じ |
| 8 | HAVING MIN(SIGN(col_x)) = MAX(SIGN(col_x)) | col_x の全ての値が全て正、または全て負、または全てゼロである |
| 9 | HAVING MIN(ABS(col_x)) = 0 | col_x は少なくとも一つのゼロを含む |
| 10 | HAVING MIN(ABS(col_x)) = MIN(col_x) | col_x はゼロ以上である(ただし、WHERE句でも同じ条件は書ける) |
| 11 | HAVING MIN(col_x) = MAX(col_x) | col_x は一つだけの値を持つか、または NULL である |
| 連番 (seq_nbr) | 名前 (name) |
|---|---|
| 1 | トム |
| 2 | ディック |
| 4 | ハリー |
| 5 | モー |