ホーム > リレーショナル・データベースの世界 >
SQLプログラミング作法
テーブル設計や SQL 作成のときに知っておいた方が良い知識、守った方が良いマナーについての文章です。多分に主観的判断が入っているので、必ず私の言うことに従わねばならないというものではありません(大体コーディング・スタイルについての議論は、純粋な善意の遣り取りから始まって、血みどろの宗教戦争で終わります)。役に立つと思ったところだけ利用してください。
- テーブル設計
- 1.名前と意味
- 2.小数の桁数
- コーディング・ルール
- 3.コメント
- 4.インデント
- 5.カンマ( , )
- 6.スペース
- 7.大文字と小文字
- 8.標準語を話そう
- 9.銃規制
- 10.相関サブクエリは避ける
- 11.共通表式を使う
- その他
- 12.予約語のハイライト
人間は「無意味」に弱い生き物です。私たちは日々、言葉から音楽から文学から仕事から人生にいたるまで、何かにつけ意味を求めたがります。あんまり無意味なものに囲まれて人生をおくると精神的に悪影響が出ますし、無意味なものを扱う能力も極めて低いのが人間という生物の特徴です。学生時代、歴史の年号を語呂合わせで覚えるという涙ぐましい(しかしそれ自身がすでに無意味な)努力をしたことがあるでしょう。
リレーショナル・データベースがシステム業界で絶大な支持を獲得した最大の理由は、無意味なものを追放したことです。すなわち、アドレスを追放したことです。アドレスを追放した後に何が残ったかといえば、名前です。名前は、固有名のように具体的な物を指すことで意味を持つものもあれば、一般名のように概念や集合を指すことで意味を持つものもあります(例外はいくらでもあるのですが、ここは素朴に考えてください)。コードやフラグのように、一見、名前には見えないものも、集合や概念を指示するという観点から見れば一般名です。例えば、性別フラグは「男」や「女」のような集合を、疾病コードは「風邪」や「虫歯」のような概念を指示する一般名です。反対に、アドレスは何の概念も指示しません。
せっかく有意味な名前だけから成る世界を作り上げたのですから、そこにまた自ら無意味な記号の羅列を持ち込む愚を犯すことはありません。列、テーブル、インデックス、制約は、名が体を表す具体的な名前を付けましょう。間違っても「A」とか「idx_1」とか「WORK」のような無意味な記号を使ってはいけません。特に、インデックスと制約は、明示的に名前を与えないと DBMS が自動的にランダムな識別子を付与してしまうので注意が必要です。また、実表の名前には気を使う人でも、インライン・ビューにはいい加減な命名をしてしまいがちです。しかしインライン・ビューを使うということは、それなりに複雑な SQL ということですから、やはり分かりやすい名前が必要です。
名前を付ける際、使っていい文字は以下の3種類です。
これは、標準 SQL で許されている文字集合です。各実装は、これ以外にも $、#、@といった特殊文字や、漢字ような2バイト文字を扱えるような独自拡張をしていますが、使うべきではありません。移植性が低下しますし、バグの原因にもなります。また標準 SQL は、先頭が文字で始まることを要請しています。これも守ってください。ダブルクォーテーション("")で囲めば、SQL の予約語を名前として使うことができますが、無用の混乱を招くだけなので、やらない方が良いでしょう。
小数データを扱うときは、実際に必要な桁数よりも多めに取っておいた方がいいでしょう。実データの桁数が小数第3位までなら、第5位ぐらいまで余裕を見ましょう。なぜなら、テーブルの小数桁数を超えるデータが投入された場合、DBMS はエラーを返すのではなく、保持可能な桁数に切り捨てたり四捨五入してテーブルに入れるからです。これに気づかないで開発を続けていると、どこかのタイミングで SQL の結果がおかしいことに面食らうことになります(最悪の場合、納品後に顧客が面食らいます)。
しかも恐ろしいことに、切り捨てるのか四捨五入するのかは実装依存とされていて、おまけに負数の切り捨て方も複数通りあります。普通は0に近づくように切り捨てるはずですが、保証はありません。念のため、使っているデータベースがどんな規則で桁数を減らしているか、チェックしておくことを薦めます。
私はコメントが好きで、よく書きます。修正履歴はもちろん、仕様書に書くほどではないけど注意すべき点や、他人が見たら不可解に思うだろうけど然るべき理由(大体は設計者の不手際)があってそのような珍妙なロジックになってしまったのだという弁明、仕様を忘れた将来の自分へのメッセージ、等々、私の書くコメントは豊富です。「コメント将軍」を名乗ってもいいぐらいです。
当然、SQL にもコメントを書くのですが、普通のプログラミング言語でコーディングする際にはコメントを付ける人が、SQL の作成時には全くコメントレスなコードを書いているのをよく見かけます。これはいただけません。SQL は段階的な実行デバッグがほとんどできないので、コードの解析時には必然的に机上デバッグ、つまり脳内シミュレーションが頼りです。従って、複雑な SQL にはコメントをこれでもかと書いておくべきです。
コメントの書き方には、以下の2通りがあります。
-- 1行コメント
-- SomeTable から col_1 を選択するよ
SELECT col_1
FROM SomeTable;
/*
複数行コメント
SomeTable から col_1 を選択するよ
*/
SELECT col_1
FROM SomeTable;
1行コメントを「--」で書くというのは、誰でも知っていると思いますが、C言語やJAVAと同じく「/* */」で複数行コメントが書けることは、意外に知られていません。これは本当にコメントを書く場合だけでなく、ソースをコメントアウトするときにも便利ですから活用してください。
また、SQL はコードの途中に空行を含むことはできないのですが、以下のようにコメントを挟むことはできます。
SELECT col_1
FROM SomeTable;
WHERE col_1 = 'a'
AND col_2 = 'b'
-- 以下の条件は col_3 が 'c'、 'd' のいずれかであることを指定します
AND col_3 IN ( 'c', 'd' );
これは、WHERE 句にずらずらと条件を並べなければならない場合など、そのままでは平坦で読みづらいコードを意味的なブロックに分ける場合に便利です。さらに、ソースと同じ行に書くこともできます。
SELECT col_1 -- SomeTable から col_1 を選択するよ
FROM SomeTable;
恐らく、世に溢れる読みづらいソースの中で最もポピュラーに見かけるのが、インデントを下げないソースです(次に多いのがモジュールを分けないソース)。特に、新入生/新入社員の頃にプログラミングを習い始めの人間は、インデントの重要性を理解できなくて、全部同じレベルからソースを書き始めます。学習用の小さなプログラムの場合、インデントがなくても混乱しないので、これは無理ないことです。しかし、プロの SE やプログラマがインデントを付けないコーディングをするのは、役立たずどころか公害もいいところです。自分のソースをメンテナンスする人間のことを気遣えない人間に、チームプレイの仕事をしてほしくありません。以下に、私が良いと思う見本と悪いと思う見本を示します。
--○良い見本
SELECT
col_1,
col_2,
col_3,
COUNT(*)
FROM tbl_A
WHERE col_1 = 'a'
AND col_2 = ( SELECT MAX(col_2)
FROM tbl_B
WHERE col_3 = 100
)
GROUP BY
col_1,
col_2,
col_3
--×悪い見本
SELECT col_1, col_2, col_3, COUNT(*)
FROM tbl_A
WHERE col_1 = 'a'
AND col_2 = (
SELECT MAX(col_2)
FROM tbl_B
WHERE col_3 = 100
)
GROUP BY col_1, col_2, col_3
まず目につくように、サブクエリについてインデントを下げます。これは必ず守ってください。「サブ(下位)」という接頭辞が付くことからも分かるように、意味的に一段下のレベルになるからです。次に、SELECT 句や GROUP BY 句において列を複数指定する場合は、これも1レベル下げます。こうすることで、「句」の区切りが明確になり、読みやすくなります。私はよほど列数が増えない限り、1行1列で書くことにしていますが、行数が増えるのが気になるなら、1行3列や5列ぐらいでもいいでしょう。しかし、次の「5.カンマ」を読んでもらえば分かりますが、1行1列の原則にはあるメリットがあるのです。
SQL では列やテーブルなどの要素の区切りにカンマを使います。ところで、このカンマというやつ、要素の後ろに置く、と思っていないでしょうか? 確かに「 col_1, col_2, col_3 」と書くとき、col_1 を書いて、その後ろにカンマを書いて、col_2 を書いて …… という順番になります。でも、それなら col_3 の後ろにカンマがないことが説明できません。そう、書く順序は記号の機能を反映するものではありません。もちろん、要素の前に置くものでもありません。それでは今度は col_1 の前にカンマがないことが説明できないからです。正解は、
カンマは要素と要素の中間に置く
です。当たり前のことですが、このことを念頭に置くと、次の書き方の発想が分かります。
SELECT
col_1
, col_2
, col_3
, col_4
FROM tbl_A;
例としてカンマを使いましたが、「+」や「−」などの二項演算子や AND、OR でも同様に書けます。AND と OR については、ごく自然にこの行頭にもってくるスタイルで書く人も多いでしょう[1]。
このスタイルの利点は二つあります。一つは、最後の col_4 を削除しても SQL がエラーにならず、そのまま使えることです。普通の書き方をしたときに col_4 を削除すると、SELECT句のラストが「 col_3, 」になってしまい、エラーになります。一々カンマも削らねばなりません。この書き方でも、最初の列を削除したときには同様の問題が起きますが、大体追加・削除の対象になるのは最後の列であることが多いものです。最初の列は重要なキーである可能性が高いので、滅多に変更されません。
二つ目の利点は、カンマがどの行でも同じ列位置に来るため、Emacs や秀丸など矩形選択の機能を持つエディタでの編集が非常にやりやすいことです。普通の書き方だと、列名の長さに応じてカンマの列位置がバラバラになるため、手間が増えます。その場合でも、タブを使えばカンマの位置は揃えられますが、今度は全行にタブを入れる手間が発生するので、コストは似たようなものです。
この書き方の唯一の欠点は、知らない人が見たときに一瞬固まってしまうことです。
SQL に限らず、どんな言語で書くときでも、ソースには適度な隙間が必要です。あんまりきつきつに詰めてしまうと、意味的な単位が不明確になり、解読する側の余計な労力も増えます。
--○良い見本
SELECT *
FROM tbl_A A, tbl_B B
WHERE ( A.col_1 >= 100 OR A.col_2 IN ( 'a', 'b' ) )
AND A.col_3 = B.col_3;
--×悪い見本
SELECT *
FROM tbl_A A,tbl_B B
WHERE (A.col_1>=100 OR A.col_2 IN ('a','b'))
AND A.col_3=B.col_3;
悪い見本を見ると分かるように、まるで「A.col_1>=100」や「A.col_3=B.col_3」で一つの文要素であるかのように見えてしまい、大変読みづらくなります。別に文法エラーにはならないのですが、きちんとスペースを入れて、要素を明示的に区切ってやる方が人間の眼には読みやすくなります。
大文字は、小文字より重要であることを表します。英文では、重要な語句を強調するときには、斜体か大文字にします。それゆえ、プログラミングにおいても、重要な語句は大文字、重要でない語句は小文字で書く文化があります。SQL の場合、大文字・小文字の使い分けはかなり業界内で共通理解が成立していて、予約語は大文字、列名やテーブル名は小文字(要素語の頭文字だけは大文字を使う流派もある[2])、ということになっています。多くの書籍でもそうなっていると思います。時々、SQL を全て大文字、あるいは全て小文字で書く人に出会いますが、私の力の及ぶ限り矯正しています。しかしこういうマナーは箸の使い方と同じで、最初に覚えた流儀からなかなか抜け出せないものであることを、たびたび痛感します。
--○メリハリがあって読みやすい
SELECT
col_1,
col_2,
col_3,
COUNT(*)
FROM tbl_A
WHERE col_1 = 'a'
AND col_2 = ( SELECT MAX(col_2)
FROM tbl_B
WHERE col_3 = 100
)
GROUP BY
col_1,
col_2,
col_3;
--×平坦で読みにくい
select
col_1,
col_2,
col_3,
count(*)
from tbl_a
where col_1 = 'a'
and col_2 = ( select max(col_2)
from tbl_b
where col_3 = 100
)
group by
col_1,
col_2,
col_3;
SQL は数ある言語の中でも方言が多いほうで、各ベンダがてんでバラバラの拡張をしてくれています。SQL にも一応、標準語が取り決められてはいるのですが(現在の最新は SQL-99)、あまり統一感を高めるための努力がされているようには思えません。特に結合まわりの文法は、およそ同じ言語とは思えないような無軌道な拡張がされています。こういう方言に無自覚なままコーディングしていると、当然の結果として、PostgresSQL → Oracle、SQLServer → MySQL のような DBMS 間の移植性が恐ろしく低くなりますし、慣れ親しんだ DBMS ではない環境でプログラミングをするときに大きな苦労をすることになります。
ちょっとした気配りで、こんな苦労は避けられるのですから、日頃から標準語を話す癖をつけましょう。
- DECODE(Oracle)、IF(MySQL)、 NVL(Oracle)等のベンダ独自拡張の関数を使ってはいけません。CASE式や COALESCE 関数を使いましょう。
- 外部結合は「LEFT OUTER JOIN」、「RIGHT OUTER JOIN」、「FULL OUTER JOIN」を使って書きましょう。(+)演算子(Oracle)、*=演算子(SQLServer)は避けましょう。
- 否定演算子は、!= ではなく、<> を使いましょう。
トリガーは極力使わないでください。特にクリティカルな処理をトリガーに任せることは避けてください。代わりにストアド・プロシージャを使いましょう。理由は以下の四つです。
- 例によって、実装ごとに文法がバラバラ
- オプティマイザによる最適化を受けられない
- エラー原因を特定するのが難しい
- 連鎖的にぶっ放されると、システム全体の動作が把握しづらくなる
1番は、程度に差はあれストアド・プロシージャについても当てはまるので、「トリガーをプロシージャで代用せよ」と説く理由としては少し弱いものですが、残りの三つの理由は極めて重大です。トリガーで実行される SQL はパフォーマンスが悪くなります。また、トリガーによる INSERT や UPDATE が失敗したとき、エラーの原因を追跡するのは骨が折れます。トリガーが実際にどのデータ変更で失敗したのかを特定するのは、プロシージャで同様のことをするよりも手間がかかるからです。その苦労は、連鎖的にトリガーが設定されていると余計大きくなります。一つのトリガーによって行なわれた更新が別のトリガーを引いて、それがさらにまた別のトリガーを引いて …… どががががががが!!!
こんな誘爆的設計をされると、データの変遷を追うことはおろか、エラー状況を再現するだけでも一苦労です。しかも、自分の預かり知らぬところでテーブルが間違った更新を受ける危険も生じます。反対にプロシージャなら、完全に自分の統制下に置くことが可能です。
また、ビジネス・ルールをトリガーで実装する例をたまに見かけますが、これも間違った使い方です。CHECK 制約やアプリケーション側で実装しましょう。
トリガーは、確かに使いどころを間違わなければ強力な武器です。しかし殺傷能力が(無用に)高いので、乱射してはいけません。
次の二つの SQL は同じ結果を返します。
--1.非相関サブクエリ
SELECT col_1
FROM tbl_A
WHERE key IN (SELECT key
FROM tbl_B );
--2.相関サブクエリ
SELECT col_1
FROM tbl_A
WHERE EXISTS (SELECT
FROM tbl_B
WHERE tbl_A.key = tbl_B.key );
さて、どちらのが理解しやすいでしょう? こう聞くと、恐らくほとんどの人が「1番」と答えると思います。1番は、クエリを実行する順番がはっきりしていて、一度に1テーブルだけを考えればよいのに対して、2番は同時に2テーブルを考慮に入れねばならないからです。ここが相関サブクエリは難しさです。ソースの可読性はコーディングの際に最優先されるべき事項ですから、当然、IN を使って書くほうがいい、ということになります ―― 原則的には。
しかし悩ましいのは、IN を使った SQL のパフォーマンスが悪い場合です。key列にインデックスが張られているなら、EXISTS で書いた方が速く動作する可能性が高くなります。そういうパフォーマンスを求めるケースでは、例外的に相関サブクエリを使うことになります。
これは、本当はあってはならないことです。同じ結果を返すクエリは、全て同一の最適な実行計画で実行されるのが理想であることは、言うまでもありません。しかし、現在のオプティマイザは、その理想を実現するほどの力を備えていません。
SQL-99 で追加された「共通表式」を使うことで、インライン・ビューを SQL の外に出すことができます。これを利用することで、保守性と可読性を高めるコーディングができます。共通表式は、次のように WITH 句を使って書きます。
-- ***** 共通表式の定義 *****
WITH viewTest
AS ( SELECT col_1, col_2,
FROM SomeTable )
-- ***** SQL本体 *****
SELECT col_1, col_2
FROM viewTest;
FROM 句にそのままインライン・ビューとして書いてもいいのですが、ビューが複雑だったり、一つの SQL の中で何度も同じビューを参照する場合には、このように WITH 句で外出しにした方がすっきり書けますし、保守も容易になります。カンマで区切ればビューは複数定義できますが、生存期間は SQL が実行される間だけなので注意してください。つまり、あくまで今まで SQL の中に組み込んでいたビューを、書く場所を移しただけということです。個人的には、同一セッション中の生存期間を持つビューなども定義できたら便利だと思いますが、まだそういう機能はありません。
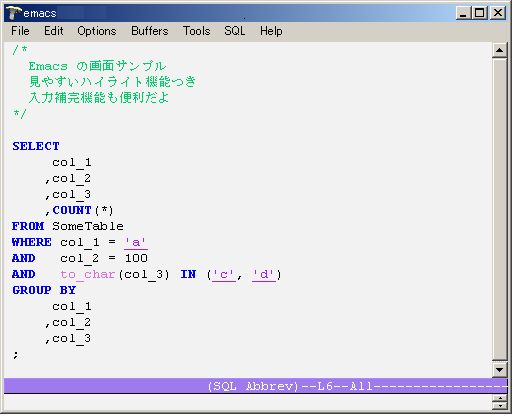
これはマナーではなく、プログラミング環境としてのエディタの選択と設定の話ですが、予約語のハイライト機能と入力補完機能のあるエディタを使うと開発効率が段違いに飛躍します。可読性が上がるし、タイプミスも減ります。これに入力補完機能を併用すれば、長いテーブル名や列名をいちいち手で打ち込む手間も省けます。私の推薦は、ここ数年間、馬鹿の一つ覚えのように繰り返している Emacs です。もともと UNIX 上のエディタとして有名でしたが、最近では Windows でも動作します。最初は癖のある使いづらいエディタと思うかもしれませんが、その苦労に見合う見返りは得られるはずです。
Emacs を使って SQL を効率よくコーディングするためには、以下の二つの機能を効果的に使う必要があります。
1.sql-mode
2.abbreviation(入力補完)
sql-mode は、その名の通り、SQL をコーディングするための機能です。予約語のハイライト(ANSI、Oracle、PostgreSQL に対応)、や自動インデント機能を備え、さらに Sql*Plus のインターフェースとして使うことができます。とりわけ、このインターフェース機能は重要です。なぜなら、SQL*Plus が Windows のエディタに劣らず貧弱だからです。コマンドの履歴はもてない、行編集もできない、入力補完もない。edit コマンドで OS のエディタを呼び出せるものの、呼び出されたエディタがメモ帳では焼け石に水です。Oracle 以外にも PostgreSQL、MySQL、DB2、SQLServer の端末として使用できます。
Let's Emacs
註
[1]
セルコは、私と反対に、カンマを行末に書くべきであると主張します。
カンマは行頭ではなく、行末に書くこと。カンマ、セミコロン、クエスチョン・マーク、ピリオドは、何かがそこで終わったことを示す視覚的サインであって、何かが始まることを示すサインではない。
(『Joe Celko's SQL Programming Style』 p.31)
しかし、私は、セルコの方こそ連結子と終端子を混同していると思います。確かに、セミコロンやピリオドは何かの終わりを示す終端子ですが、カンマは要素と要素を結ぶ連結子であり、その意味で AND や OR などと同じ機能を持ちます。従って、行頭に書くことは意味的におかしくないと思います。
[2]
例えば PlayStation、McDonald のように書く記法で、大文字をラクダのこぶに見たてて、
キャメルケースと呼ばれます。JAVA のクラス名などに見られるように、コンピュータ業界でも多用されています。
Copyright (C) ミック
作成日:2006/01/13
最終更新日:2006/07/13

