-
SQL 的な観点から考えることを学ぶことは、多くのプログラマにとって一つの飛躍である。きっとあなた方の多くは、そのキャリアの大半を手続き型のコードを書いて過ごしてきたことだろう。そしてある日突然、非-手続き型のコードに取り組まねばならなくなる。そこで肝心なのは、順序から集合へ思考パターンを変えることだ。
J.セルコ[1]
セルコが正しく言い当てたように、SQLの考え方を習得するときに最大の障壁となるのが、私たちが慣れ親しんだ手続き型言語の考え方です。具体的に言えば、代入・分岐・ループを基本的な処理単位として、システム全体をこの基本的な処理へ分割する発想です。同様に、ファイルシステムもまた、大量データをレコードという小さな単位に分割して扱います。どちらにも共通しているのは、複雑な処理を単純な処理の組み合わせと見なす還元論的な考え方です。
SQL の考え方は、ある意味でその対極を行きます。SQL には代入やループなどの手続きは一切現れませんし、データもレコードではなく、もっと複合的な集合の単位で扱われます。言ってみれば、SQL とリレーショナル・データベースの発想は、どちらかというと全体論的なのです。
SQL を無理やり手続き的に組もうとすると、読むに堪えない長大で複雑な SQL になるか、安易にプロシージャとカーソルに手を出して、慣れ親しんだ手続き型の世界へ舞い戻ることになります。
SQL に習熟するためには、SQL とリレーショナル・データベースの世界を支配する独自の原理を理解し、それを使いこなさねばなりません。理解するだけではダメで、原理や理論は現場の実践に生きて初めて命を持ちます。これは、このサイト全体を貫くテーマでもあります。SQL は、その機能を十全に発揮させてやれば、手続き型言語に劣らぬ力を発揮する言語なのですから。
そこでこのコラムでは、手続き型言語からSQLへ発想を切り替えるための指針を、いくつかのポイントにまとめてみたいと思います。
1.IF 文や CASE 文は、CASE 式で置き換える。SQL はむしろ関数型言語と考え方が近い。
手続き型言語では、「文」の単位で処理を分岐させます。一方、SQLでは、文の中の「式」の単位で分岐させます。一つのSELECT文やUPDATE文の中で、非常に複雑で柔軟な分岐を表現することが可能ですが、そのために威力を発揮するのがCASE式(CASE expression)です。 そう、CASE「文」(statement)ではなく「式」という名前が物語るように、CASE式は 1 + (2 - 4) や (x * y ) / z といった式の仲間であり、実行時には一つの値に評価されます。式の仲間なので、「1 + 1」が書ける場所ならどこにでも書くことができますし[2]、最終的に一つの値に定まるために、集約関数の引数にとることもできるのです。
手続き型言語の発想に囚われたまま、文の単位で分岐させようと大量の SQL をコーディングしている例を見かけることがありますが、「式」の単位で分岐させれば、はるかに簡潔で読みやすいクエリを書くことができます。
入力に対して一つの値を返すという点で、CASE 式は、一種の関数です。そのため、CASE 式を使うときの思考は、Lisp などの関数型言語を使うときの思考に近くなります[3]。Lisp にも、cond や case という分岐を記述するための機能がありますが、手続き型言語の IF 文などと違って、これらは関数です。そのため、CASE式 と同様、文ではなく式(関数)の単位で分岐し、どちらも一つの値を返します(Lisp ではリストも一つの値と見なすところが SQL と違いますが、いずれは SQL も複合的なデータ型を扱えるようになるでしょう)。
ためしに、両者を並べてみましょう。
'Lisp の cond 関数による分岐
cond(
((= x 1) 'xは1です')
((= x 2) 'xは2です')
(t 'xはそれ以外の数です'))
--SQL の CASE 式による分岐
CASE WHEN x = 1 THEN 'xは1です'
WHEN x = 2 THEN 'xは2です'
ELSE 'xはそれ以外の数です'
END
このように、Lisp の記号法が逆ポーランド記法である点を除けば、やっていることは同じです。条件を入れ子にできるので、階層的な分岐も記述できる点まで瓜二つです。だから、関数型言語に慣れている人は、SQL の CASE 式もすぐ理解できますし、逆もまた然りです。プログラミング言語間では、よく信奉者同士の間に小競り合いが起きますが、それよりは、架橋できるポイントを探して、複数の言語の理解を深めていくほうが生産的でしょう。
参考 → 「CASE式のススメ」
2.ループは GROUP BY 句と相関サブクエリで置き換える。
SQL には文単位でのループも存在しません。カーソルを使えば別ですが、あれは手続き型の世界の話で、ピュア SQL とは無関係です。SQL は、その設計の最初の構想から、ループを排除することを目的の一つとしていたのです[4]。
特に、手続き型言語でループが利用される定番の処理に「コントロール・ブレイク」がありますが、これは SQL では GROUP BY 句と相関サブクエリを使って表現することができます。相関サブクエリは、SQL を習い始めの初級者がつまづきやすいポイントの一つですが、処理単位を分割して考えるための大変有効な技術であることを理解しましょう。手続き型言語においてループを使っていた処理は、この二つの機能で完全にカバーできます。
時々、手続き型の発想に凝り固まったプログラマがループに固執して、GROUP BY で集約すればすむところを、ヒラで SELECT した結果をカーソルで一行づつループさせて集約を行った、という笑うに笑えない実話を聞くことがあります。
皆さん、忘れないでください。SQL にループはないし、なくても別に困らないのです。
参考 → 「相関サブクエリで行と行を比較する」、「SQLで集合演算」
3.テーブルの行に順序はない。
手続き型言語とファイルシステムに慣れ親しんだエンジニア ―― 要するに私たちのほとんど全て ―― は、どうしてもリレーショナル・データベースの「テーブル」を「ファイル」とのアナロジーに頼って理解しようとする癖があります。
これは、ある意味で仕方ないことではあります。未知の概念を理解しようとするとき、既に自分が理解している概念を使って把握する、というのは最初の第一歩としては有効な方法ですし、ほとんど唯一の方法です。しかし、ある段階まで成長したら、古い殻は脱ぎ捨てねばなりません。テーブルをファイルと見なすことの最大の危険は、行が順序を持つと誤解してしまうことです。
ファイルにとって、行の順序はとても大事なものです。テキストファイルを開いたときに、行の順番がデタラメに表示されるなどということがあったら、使いものになりません。しかし、リレーショナル・データベースにおいて、テーブルを読み出したときには、まさにそういう事態が生じます。INSERT した順序で読み出されるという保証はありませんし、SQL でのデータ操作においてもその必要はないからです。SQL は順序に頼らなくても十分やっていけます。
リレーショナル・データベースのテーブル(関係)は、数学の「集合(set)」の概念に起源を持ちます。敢えて順序という目に見える概念を捨て、抽象度を可能な限り高めるために考えられた概念がテーブルです。元々、まったく異なる起源を持つ概念同士なのだから、ファイルとテーブルが齟齬をきたすのも無理はありません。テーブルとは、データが順序良く整理されたバインダーよりは、色々なおもちゃが雑多に放り込まれた「箱」や「袋」のイメージに近いでしょう。
この点をわきまえず、順序に頼った発想をすると、無駄に複雑で、移植性もないコードが生み出されてしまいます。たとえば、ビューの定義に ORDER BY 句を指定したり(こんなことを許す実装にも問題がありますが)、むやみに OLAP 関数を使って不必要にコードを複雑にしたり、また、Oracle の rownum のような実装依存の行番号列を使う誘惑に駆られるのは、順序指向の典型的な弊害です。
かつて、物理学の泰斗ファインマンは、量子力学を初めて習う学生に向かって「この新しい学問を、君が今まで習ってきたニュートン力学とのアナロジーに頼って理解しようとしてはいけない」と釘を刺しました[5]。「量子は、君がこれまでに見てきた何物にも似ていないから」と。
新しい概念を学ぶときは、一度古い概念を捨てるか、少なくともカッコに入れて相対化する必要があります。これは、先賢たちが昔から使ってきた正攻法です。でも、正攻法は常に一番難しい。慣れ親しんだスタイルを離れるときは、知性だけでなく勇気がいるからです。
参考 → 「HAVING句の力」、 「帰ってきたHAVING句」、 「SQLで数列を扱う」
4.テーブルを集合と見なそう。
上でも述べたように、テーブルはファイルよりもずっと抽象度の高い存在です。ファイルは、その記憶方法に緊密に結び付けられていますが、SQL でテーブルやビューを扱うときは、そのメモリ上での扱いを一切気にする必要はありません(パフォーマンスを除けば)。私たちはどうしてもテーブルをファイルと同じと見なしてしまいますが、実際には、一テーブルが一つのファイルに対応しているわけではないし、ファイルのように一行づつ読み出されるわけでもありません。
テーブルの抽象性を理解するために一番いい方法は、自己結合を使うことです。というのも、自己結合は、まさに集合という概念の抽象度(自由度、と言ってもいい)の高さゆえに可能となった技術だからです。SQLの中では、同じテーブルに違う名前を与えて、あたかもそれらが別のテーブルとして存在しているかのように扱うことができます。すなわち、自己結合を使えば、私たちは好きな数だけ集合を追加し、操作することができるようになるのです。この自由度の高さが、SQLの魅力であり、また強力さでもあるのです。この点を理解しないと、SQL とリレーショナル・データベースの楽しさは分からない。
参考 → 「自己結合の使い方」
5.EXISTS と「量化」の概念を理解しよう。
SQL を支える理論は、集合論のほかにもう一つあります。それが述語論理(predicate logic)、特に SQL の場合、もう少し限定して一階述語論理です。述語論理は、100年ほどの歴史を持ち、現在の論理学において標準的な論理とされています(だから、論理学の分野で何も断り無しに「論理」というと、この一階述語論理を意味します)。
SQL において述語論理が特に力を発揮する場面は、やはり集合論と同じく「複数行を一単位として」取り扱うときです。述語論理は、複数の対象をひとまとめにして扱う道具として「量化子」という述語を持っています。これは、SQL でいうところの EXISTS 述語です。
EXISTS の使い方は、IN とよく似ているのでまだ理解しやすいのですが、本当に使いこなさなければならないのは、NOT EXISTS の方です。というのも、SQL は量化子の実装に手を抜いた(?)ので、二つあるうちの片一方の量化子しか持っていません。そのため、SQL が持っていない全称量化子については、NOT EXISTS を使って表現するしかありません。
NOT EXISTS を使ったクエリは、正直言ってあまり読みやすいものではありません。しかも、同じことを HAVING 句や ALL 述語を使って表現できます。そのため、NOT EXISTS は多くのプログラマから敬遠されています。しかし、NOT EXISTS には、一つ大きな利点があります。それは、HAVING 句や ALL 述語に比べてパフォーマンスが非常によい、ということです。
可読性を優先させられる局面では、あえて NOT EXISTS で全称文を書く必要はありません。しかし、どうしてもパフォーマンスを譲れないケースは必ずあります。そのためにも、ド・モルガンの法則を利用して NOT EXISTS で全称量化を表す技術を、是非とも理解しておいてほしいのです。
参考 → 「SQLの中の述語論理」、 「SQLで数列を扱う」
6.HAVING 句の真価を学ぶ。
HAVING 句は、SQL の機能の中で最も軽視されているといっていいでしょう。しかし、それはあまりに勿体無い話です。HAVING 句は、SQL の集合指向言語としてのエッセンスが凝縮された機能だからです。SQL 的な考え方を身に付ける一番手っ取り早い方法が、HAVING 句の使い方を学ぶことだ、というのは私の持論です。
というのも、WHERE 句と違って、HAVING 句はまさに集合そのものに対する条件を設定する句であるため、これを使いこなすためには、データを集合の観点から把握することが必須だからです。HAVING 句の練習をすることによって、知らず知らずのうちに集合指向の概念についても分かるようになる、という仕組みです。そして、HAVING 句を使ってデータを操作するときに活躍するのが、次に紹介する「円を描く」という方法論なのです。
参考 → 「HAVING句の力」、 「帰ってきたHAVING句」
7.四角を描くな、円を描け。
手続き型言語でのコーディングを助ける視覚的なツールには、歴史的に多くの積み重ねがあります。特に1970年代に編み出され、長い年月をかけて発展してきた構造図(Structure diagram)とDFD(Data Flow Diagram)は、大きな効果を発揮するツールとして定着しています。こうした図では、手続き(処理)が箱で、データの流れが矢印で表されるのが一般的です。
しかし、この昔ながらの道具は、SQL とリレーショナル・データベースの理解を助ける目的には、はっきり言って不向きです。SQL は、ただ欲しいデータの条件を記述するだけで、そこに動的な処理は一切表れません。テーブルも静的なデータを表現するだけです(それが「宣言型」の意味)。いわば私たちは、「35歳まで」とか「未経験可」とか色々な条件を付けて求人募集の広告を出しているようなものです。実際に駆けずり回って条件に見合う人材を探すのは、データベースの仕事です。
このような静的データ・モデルを一番的確に表す視覚図は、今のところベン図、すなわち「円」です。それも、入れ子の円を描くことが、SQL の理解を飛躍的に高めます。なぜなら、SQL においては入れ子集合の使い方が一つの鍵になるからです。GROUP BY や PARTITION BY は、テーブルを「類」という部分集合に切り分けますし[6]、ノイマン型の再帰集合や木構造を扱うための入れ子集合モデルでも、入れ子集合が大活躍します。入れ子の集合(=再帰的集合)をうまくイメージして、使いこなせるようになることが、中級 SQL プログラミングの肝と言っていいでしょう。
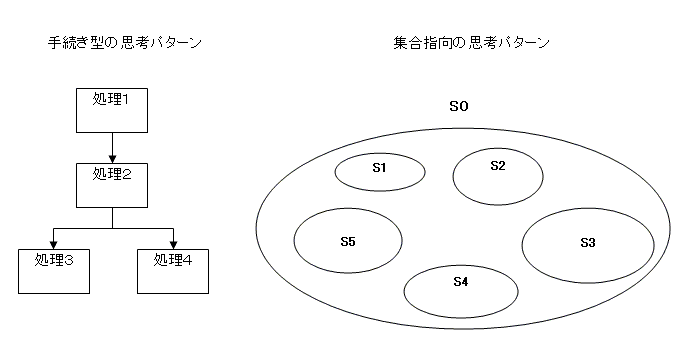
かつてアクション映画界のカリスマ、ブルース・リーは「頭で考えるな、肌でつかめ」という名言を残しましたが、データベース界のカリスマ、セルコもやはり「箱と矢印を描くな、円を描け」という名言を残しています。痺れる言葉じゃありませんか。
参考 → 「HAVING句の力」、 「SQLで集合演算」、 「SQLで木と階層構造のデータを扱う」
注
[1] J.セルコ, "Thinking in SQL"
[2] もっと言うと定数が書ける場所にはどこにでも書けます。定数というのは、要するに「変数が0個の式」と同義だからです。
[3] セルコもまた、SQL と関数型言語の親近性を指摘しています。『SQL Puzzles & Answers 2nd』"Puzzle 61 SORT A STRING" を参照。
[4] このことは関係モデルの創始者であるコッド自身の言葉からも明らかです。
「関係操作では、関係全体をまとめて操作の対象とする。目的は繰り返し(ループ)をなくすることである。いやしくも末端利用者の生産性を考えようというのであれば、この要件を欠くことはできないし、応用プログラマの生産性向上に有益であることも明らかである。」
[5] リチャード・P・ファインマン『ファインマン物理学 (5)』(岩波書店, 1986)
[6] GROUP BY と PARTITION BY の詳細については、「GROUP BY と PARTITION BY」も参照。
Copyright (C) ミック
作成日:2007/06/07
最終更新日:2017/06/22

 Tweet
Tweet