ホーム > リレーショナル・データベースの世界 >
『SQLパズル 第2版』サポートページ
このサイトは、私が訳者を務めたジョー・セルコ『SQLパズル 第2版』 (翔泳社, 2007)のサポートページです。主な内容としては、本文中に掲載されていないテーブル定義文やサンプルデータ、および実装に依存するコードについての注意や書籍には載っていない別解の紹介などです。なかなか歯ごたえのある本で、漫然と読んでいるだけでは理解できない部分も多いでしょう。そんなときは、このサイトの SQL を実際に実行してみるといいでしょう。ぜひ、読者の皆さんの学習に役立てていただきたいと思います。疑問、間違いの指摘、新たな解法のアイデアなども随時募集しております。受付は、メール、ゲストブック、ブログのいずれからでもどうぞ。
(翔泳社, 2007)のサポートページです。主な内容としては、本文中に掲載されていないテーブル定義文やサンプルデータ、および実装に依存するコードについての注意や書籍には載っていない別解の紹介などです。なかなか歯ごたえのある本で、漫然と読んでいるだけでは理解できない部分も多いでしょう。そんなときは、このサイトの SQL を実際に実行してみるといいでしょう。ぜひ、読者の皆さんの学習に役立てていただきたいと思います。疑問、間違いの指摘、新たな解法のアイデアなども随時募集しております。受付は、メール、ゲストブック、ブログのいずれからでもどうぞ。
注意事項:
- 書籍の本文に掲載されているコードは、版元の翔泳社のサイトよりダウンロードできます。まずこちらからコードを取得しましょう。
- 以下に掲載するコードは、Oracle でも動作するように、テーブルの相関名を付けるときのキーワード「AS」を省略しています。
- OLAP 関数を使うコードは、現在のところ、Oracle、DB2、SQLServer(2005バージョン以上) でのみ動作します。PostgreSQL、MySQL では動きません。
第1問 会計年度テーブル
記念すべき第1問は、テーブル定義と制約の付け方から。こういうのをしょっぱなに持ってくるあたりがしびー。実際、制約は軽視されがちな点ですが、データを妥当に保つ意識を持つことは、DB エンジニアにとって全てに勝る基本です。
サンプルデータ
CREATE TABLE FiscalYearTable1
(fiscal_year INTEGER NOT NULL PRIMARY KEY,
start_date DATE NOT NULL,
CONSTRAINT valid_start_date
CHECK((EXTRACT (YEAR FROM start_date) = fiscal_year - 1)
AND (EXTRACT (MONTH FROM start_date) = 10)
AND (EXTRACT (DAY FROM start_date) = 01)),
end_date DATE NOT NULL,
CONSTRAINT valid_end_date
CHECK((EXTRACT (YEAR FROM end_date) = fiscal_year)
AND (EXTRACT (MONTH FROM end_date) = 09)
AND (EXTRACT (DAY FROM end_date) = 30)),
CONSTRAINT valid_interval
CHECK ((end_date - start_date) = INTERVAL '365' DAY));
--正常データ
INSERT INTO FiscalYearTable1 VALUES(1995, '1994-10-01', '1995-09-30');
INSERT INTO FiscalYearTable1 VALUES(1997, '1996-10-01', '1997-09-30');
INSERT INTO FiscalYearTable1 VALUES(1998, '1997-10-01', '1998-09-30');
--エラーデータ
INSERT INTO FiscalYearTable1 VALUES(1996, '1995-10-01', '1996-08-30'); -- 終了日が8月
INSERT INTO FiscalYearTable1 VALUES(1999, '1998-10-02', '1999-09-30'); -- 開始日が2日
なお、訳注で注意を促したように、INTERVAL 定数の表記には実装ごとにかなり揺れがあります。Oracle は、正しく標準 SQL を守っているので、本文中のコードをほぼそのまま使えます(ただしこの問題に関して言うと、日付同士の引き算結果が整数型になる仕様となっているので、そもそも INTERVAL が不要)。PostgreSQL は、 「INTERVAL '359 DAYS'」のように、単位までをシングルクォートで囲みます。しかも、複数の場合は単位まで複数形にせねばなりません。MySQL は「INTERVAL 359 DAY」のように、シングルクォートを一切使いません。
参考:
第2問 欠勤
引き続き、日付の扱いについての問題。今度は日付が連続しているかどうかを調べます。
サンプルデータ
CREATE TABLE Personnel
(emp_id INTEGER NOT NULL PRIMARY KEY);
CREATE TABLE ExcuseList
( reason_code CHAR (40) NOT NULL PRIMARY KEY);
CREATE TABLE Absenteeism (
emp_id INTEGER NOT NULL ,
absent_date DATE NOT NULL,
reason_code CHAR (40) NOT NULL ,
severity_points INTEGER NOT NULL CHECK (severity_points BETWEEN 0 AND 4),
PRIMARY KEY (emp_id, absent_date));
INSERT INTO Personnel VALUES(1);
INSERT INTO Personnel VALUES(2);
INSERT INTO Absenteeism VALUES(1, '2007-05-01', 'ずる', 4);
INSERT INTO Absenteeism VALUES(1, '2007-05-02', '病気', 2); --0になる
INSERT INTO Absenteeism VALUES(1, '2007-05-03', '病気', 2); --0になる
INSERT INTO Absenteeism VALUES(1, '2007-05-05', 'ケガ', 1);
INSERT INTO Absenteeism VALUES(1, '2007-05-06', '病気', 3); --0になる
INSERT INTO Absenteeism VALUES(2, '2007-05-01', 'ずる', 4);
INSERT INTO Absenteeism VALUES(2, '2007-05-03', '病気', 2);
INSERT INTO Absenteeism VALUES(2, '2007-05-05', 'サボリ', 2);
INSERT INTO Absenteeism VALUES(2, '2007-05-06', 'サボリ', 2); --0になる
「0になる」とコメントのある行が、答え1と2の UPDATE で罰点が0に更新される行です。
--連続する休みを病欠扱いにする
emp_id absent_d reason_code severity_points
------ -------- ----------------- ----------------
1 07-05-01 ずる 4
1 07-05-02 long term illness 0
1 07-05-03 long term illness 0
1 07-05-05 病気 3
1 07-05-06 long term illness 0
2 07-05-03 病気 2
2 07-05-05 サボリ 2
2 07-05-06 long term illness 0
カレント行の日付に対して「INTERVAL '1' DAY」で1日足すことによって、ドミノ倒しのように連続休暇の有無を探索しているわけですね。もちろん、数値の場合も同じように連番を探すことが可能です。その場合は INTERVAL を使う必要はないので、もっと簡単です。
第3問 忙しい麻酔医
期間の重複を調べるという問題です。この手の問題では、一点でのみ重なる期間を重複と見なすかどうかがポイントになります。この問題では重複と見なしません。例えば、13:30に終わる処置60と同時刻に始まる処置70は、重ならないという扱いになります。
サンプルデータ
CREATE TABLE Procs(
proc_id INTEGER,
anest_name VARCHAR(64),
start_time TIMESTAMP,
end_time TIMESTAMP );
INSERT INTO Procs VALUES( 10, 'Baker', '01-07-01 08:00', '01-07-01 11:00');
INSERT INTO Procs VALUES( 20, 'Baker', '01-07-01 09:00', '01-07-01 13:00');
INSERT INTO Procs VALUES( 30, 'Dow' , '01-07-01 09:00', '01-07-01 15:30');
INSERT INTO Procs VALUES( 40, 'Dow' , '01-07-01 08:00', '01-07-01 13:30');
INSERT INTO Procs VALUES( 50, 'Dow' , '01-07-01 10:00', '01-07-01 11:30');
INSERT INTO Procs VALUES( 60, 'Dow' , '01-07-01 12:30', '01-07-01 13:30');
INSERT INTO Procs VALUES( 70, 'Dow' , '01-07-01 13:30', '01-07-01 14:30');
INSERT INTO Procs VALUES( 80, 'Dow' , '01-07-01 18:00', '01-07-01 19:00');
この問題はおそらく、OVERLAPS 述語を使っても解くことができると思います。というのは、OVERLAPS も端でのみ一致するケースを重複にカウントしないからです。練習問題として考えてみてください。
第4問 入館証
この問題のちょっと厄介なところは、チェック制約内でのテーブル参照をサポートしている DB がまだほとんどない、ということです。そのため、この制約は削除した形のテーブル定義で進めます。あと、Personnel テーブルへの外部キーも、問題の本質に関わらないので削除します。
サンプルデータ
--答え1用
CREATE TABLE Badges
(badge_nbr INTEGER NOT NULL PRIMARY KEY,
emp_id INTEGER NOT NULL,
issued_date DATE NOT NULL,
badge_status CHAR(1) NOT NULL
CHECK (badge_status IN ('A', 'I')));
INSERT INTO Badges VALUES(100, 1, '2007-01-01', 'I');
INSERT INTO Badges VALUES(200, 1, '2007-02-01', 'I'); --社員1番の最新バッジ
INSERT INTO Badges VALUES(300, 2, '2007-03-01', 'I'); --社員2番の最新バッジ
INSERT INTO Badges VALUES(400, 3, '2007-03-01', 'I');
INSERT INTO Badges VALUES(500, 3, '2007-04-01', 'I');
INSERT INTO Badges VALUES(600, 3, '2007-05-01', 'I'); --社員3番の最新バッジ
--答え2用
CREATE TABLE Badges
(badge_nbr INTEGER NOT NULL PRIMARY KEY,
emp_id INTEGER NOT NULL,
issued_date DATE NOT NULL,
badge_seq INTEGER NOT NULL CHECK (badge_seq > 0),
UNIQUE (emp_id, badge_seq));
INSERT INTO Badges VALUES(100, 1, '2007-01-01', 1);
INSERT INTO Badges VALUES(200, 1, '2007-02-01', 2); --社員1番の最新バッジ
INSERT INTO Badges VALUES(10, 2, '2007-03-01', 1); --社員2番の最新バッジ
INSERT INTO Badges VALUES(2000,3, '2007-03-01', 1);
INSERT INTO Badges VALUES(3, 3, '2007-04-01', 2);
INSERT INTO Badges VALUES(50, 3, '2007-05-01', 3); --社員3番の最新バッジ
答え1のUPDATE文は、「多くのDBがエラーを返す」と書かれていますが、私が確認した限り、Oracle と PostgreSQL では正しく動きます。MySQL ではエラーになります。
-- アクティブなバッジを割り振る
badge_nbr emp_id issued_d b
--------- ------ -------- -
100 1 07-01-01 I
200 1 07-02-01 A
300 2 07-03-01 A
400 3 07-03-01 I
500 3 07-04-01 I
600 3 07-05-01 A
UPDATE 文の最初の条件の ALL 述語は、ある社員が持っているバッジの状態が全て「I」である、というもの。そういう社員を見つけたら、二番目の条件で、その社員が持っている最新日付のバッジを探して「A」にしています。
答え2も、日付を連番に置き換えたぐらいで大きな差はないのですが、確かにバッジの個数が分かるというのはメリットですね。
--最大の連番を持つのがアクティブなバッジ
SELECT emp_id, badge_nbr
FROM Badges B1
WHERE badge_seq = (SELECT MAX(badge_seq)
FROM Badges B2
WHERE B1.emp_id = B2.emp_id);
emp_id badge_nbr
------ ---------
1 200
2 10
3 50
連番をリセットする SQL のサブクエリは、自己結合でランキングを算出するときに使う再帰集合のクエリと同じです。主キーを結合キーに使えば、歯抜けのない連番が生成できるので、ROW_NUMBER の代わりに使えます。
ちなみにここで ROW_NUMBER を使おうと考えた人もいるかもしれませんが、SET 句で OLAP 関数が使えるのは DB2 だけです。Oracle などではエラーになります。
--DB2でのみ可能
UPDATE Badges
SET badge_seq = ROW_NUMBER()
OVER (PARTITION BY emp_id ORDER BY badge_seq);
Oracle などで、どうしても ROW_NUMBER を使いたければ使うこともできます。ただし、ちょっと複雑な SQL を書かねばなりません。挑戦してみてください。
参考:
第5問 アルファベット
意外な角度から SQL の集合指向性に光を当てるちょっと面白いパズル。文字列を「文字の集合」と見なすのがポイントですね。ここでは一番複雑な all_alpha 列(全てアルファベット)だけでテーブルを作ります。
サンプルデータ
--答え2用
--PostgreSQL
CREATE TABLE Foobar
(all_alpha VARCHAR(6) NOT NULL
CHECK (all_alpha SIMILAR TO '[a-zA-Z]+') );
--Oracle
CREATE TABLE Foobar
(all_alpha VARCHAR(6) NOT NULL
CHECK (REGEXP_LIKE(all_alpha, '^[a-zA-Z]+$') ));
--正常データ
INSERT INTO Foobar VALUES(''); --Oracleでは正常だが、PostgreSQLではエラーと見なされる
INSERT INTO Foobar VALUES('a');
INSERT INTO Foobar VALUES('A');
INSERT INTO Foobar VALUES('aA');
INSERT INTO Foobar VALUES('abcdef');
INSERT INTO Foobar VALUES('ABCDEF');
INSERT INTO Foobar VALUES('AbCdEf');
--エラーデータ
INSERT INTO Foobar VALUES(NULL);
INSERT INTO Foobar VALUES('a1aaaa');
INSERT INTO Foobar VALUES('ceeg0d');
INSERT INTO Foobar VALUES('Aあ');
INSERT INTO Foobar VALUES('123456');
INSERT INTO Foobar VALUES('s23');
INSERT INTO Foobar VALUES('1a3456');
INSERT INTO Foobar VALUES('N23456');
答え2の TRANSLATE 関数を使う方法は、「アルファベットならば文字 x へ変換する」という処理を施した後の文字列が「xxxxxx」と等しいかどうか、というテストを行うものですが、あまり一般的に使える方法ではないようです。
むしろ答え3の正規表現の方がこれから主流になるでしょう。PostgreSQL の構文は見たままですが、Oracle の正規表現は、デフォルトで 部分一致検索の扱いになっているので、完全一致を表現するには先頭(^)と末尾($)の指定も必要です。
第6問 ホテルの予約
再び、重複する日付期間を扱う問題です。要件はとっても明確なので多くを解説する必要はないでしょうが、やはり CHECK 制約でサブクエリを使えないことがネックとなって、少し工夫を要する問題となっています。
サンプルデータ
CREATE TABLE Hotel
(room_nbr INTEGER NOT NULL,
arrival_date DATE NOT NULL,
departure_date DATE NOT NULL,
guest_name CHAR(30) NOT NULL,
PRIMARY KEY (room_nbr, arrival_date),
CHECK (departure_date >= arrival_date));
このパズルで面白いのは、答え3の、Oracle の「WITH CHECK OPTION」付きのビュー HotelStays を使う方法でしょう。
-- OK
INSERT INTO HotelStays VALUES (1, '2008-01-01', '2008-01-03', 'Coe');
-- OK
INSERT INTO HotelStays VALUES (1, '2008-01-03', '2008-01-05', 'Doe');
-- 失敗! Coe氏とかぶる
INSERT INTO HotelStays VALUES (1, '2008-01-02', '2008-01-05', 'Roe');
Roe 氏は、Coe 氏と宿泊期間がかぶるので INSERT に失敗します。ポイントは、あくまで INSERT 対象が HotelStays ビューであって実テーブルではないことです。実テーブルへの挿入時には、WITH CHECK OPTION は発動しません。
第7問 ファイルのバージョン管理
SQL は集合論と述語論理を基礎とする極めて抽象性の高い言語です。というと難しく聞こえるかもしれませんが、誤解を恐れず平たく言ってしまえば「ポインタやアドレスなどの低レベルなロケータを気にしなくていい」というとっても有難い話なのです。プログラミング言語の歴史をひもとけば、抽象性を高める方向に発展を遂げてきていることは明らかです。C言語やアセンブラに比べれば、Java、Perl、Ruby などは明らかにユーザからポインタを隠蔽しようと努力しています。SQL はその徹底を極限まで推し進めた言語の一形態です。
さてこの問題は、ポインタ・チェインの構造をそのままテーブルに写し取ってしまって四苦八苦しているスティーブ君からのお便りで始まります。彼の作ったテーブルを見たら分かるように、これは隣接リストモデルのテーブルです。ポインタ・チェインを扱うテーブルとしては非常にポピュラーなものであり、決して彼が自分で卑下するように特別に酷いテーブル設計ではないのですが、でもはっきり言って、「SQL的ではない」のですね。これが。
スティーブの考えた隣接リストモデルのデータ構造(chain=1のケース)

代わりにセルコが出す案は、お得意の「入れ子集合モデル」です。ただし、今回は木の構造が単線的でとっても簡単なので、普通の入れ子集合モデルが左端(lft)と右端(rgt)の座標を持つのに対し、半径(next)一つで済ませる簡略版です。入れ子の作り方も規則的なので、これで十分です。
この問題に関しては、サンプルコードは本文中に完全に含まれているので、ここでは割愛します。
参考:
第8問 プリンタの割り当て
SQL を負荷分散システムに組み込むような感じの問題です。実用的でよい問題ですが、それ以上に、SQL の根幹にかかわる重大な特性(というか欠点)を浮き彫りにしてみせた面白さがあります。
サンプルデータ
--答え1用
CREATE TABLE PrinterControl
(user_id_start CHAR(10) NOT NULL,
user_id_finish CHAR(10) NOT NULL,
printer_name CHAR(4) NOT NULL,
printer_description CHAR(40) NOT NULL,
PRIMARY KEY (user_id_start, user_id_finish));
INSERT INTO PrinterControl VALUES( 'chacha', 'chacha', 'LPT1', '一階のプリンタ' );
INSERT INTO PrinterControl VALUES( 'lee' , 'lee' , 'LPT2', '二階のプリンタ' );
INSERT INTO PrinterControl VALUES( 'thomas', 'thomas', 'LPT3', '三階のプリンタ' );
INSERT INTO PrinterControl VALUES( 'a', 'mzzzzzzz' , 'LPT4', '共有プリンタ #1' );
INSERT INTO PrinterControl VALUES( 'n', 'zzzzzzzz' , 'LPT5', '共有プリンタ #2' );
--答え2、3用
CREATE TABLE PrinterControl
(user_id CHAR(10), -- NULLは空きプリンタを意味する
printer_name CHAR(4) NOT NULL PRIMARY KEY,
printer_description CHAR(40) NOT NULL);
INSERT INTO PrinterControl VALUES( 'chacha', 'LPT1', '一階のプリンタ');
INSERT INTO PrinterControl VALUES( 'lee' , 'LPT2', '二階のプリンタ');
INSERT INTO PrinterControl VALUES( 'thomas', 'LPT3', '三階のプリンタ' );
INSERT INTO PrinterControl VALUES( NULL , 'LPT4', '共有プリンタ' );
INSERT INTO PrinterControl VALUES( NULL , 'LPT5', '共有プリンタ' );
--答え4用
CREATE TABLE PrinterControl
(user_id CHAR(10), -- NULLは空きプリンタを意味する
printer_name CHAR(4) NOT NULL PRIMARY KEY,
assignable_flag CHAR(1) DEFAULT 'Y' NOT NULL
CHECK (assignable_flag IN ('Y', 'N')),
printer_description CHAR(40) NOT NULL);
INSERT INTO PrinterControl VALUES( 'chacha', 'LPT1', 'N', '一階のプリンタ');
INSERT INTO PrinterControl VALUES( 'lee' , 'LPT2', 'N', '二階のプリンタ');
INSERT INTO PrinterControl VALUES( 'thomas', 'LPT3', 'N', '三階のプリンタ' );
INSERT INTO PrinterControl VALUES( NULL , 'LPT4', 'Y', '共有プリンタ #1' );
INSERT INTO PrinterControl VALUES( NULL , 'LPT5', 'Y', '共有プリンタ #2' );
答え1と4は、非常に明快でオーソドックスな解法です。答え4でちょっと注意が必要な点は、固定ユーザの使うプリンタについては、割り当て可能フラグをデフォルトで「N」にしておくことです。こうしないと、共有プリンタの NULL クリア UPDATE の条件の「assignable_flag = 'Y'」が活きてきません。あくまで更新対象を割り当てフラグが「Y」のプリンタだけに制限するのがこの解の意図です。
一方、やってくれるぜ、という感じのトリッキーな解が答え2と3です。空集合に集約関数適用すると NULL が返るという SQL の奇妙な特性を利用した、ある意味で意地の悪い解答です。ちなみに、両方とも PostgreSQL では動作しますが、Oracle ではエラーになります。
参考:
第9問 席空いてますか?
SQL で連番を扱うとき、大きな問題となるのが、欠番の存在です。この問題の主眼は、欠番の始点と終点をいかにして把握するか、というものです。手続き型言語とは 対極をいく SQL の発想を学べる良問。
サンプルデータ
CREATE TABLE Restaurant( seat INTEGER );
INSERT INTO Restaurant VALUES(1);
INSERT INTO Restaurant VALUES(3);
INSERT INTO Restaurant VALUES(4);
INSERT INTO Restaurant VALUES(7);
--答え3の番兵用
INSERT INTO Restaurant VALUES(0);
INSERT INTO Restaurant VALUES(1001);
ここでは、とても見事なレムレーの答え4と、OLAP 関数を使う答え5の結果をお見せしましょう。
--答え4の結果:
start finish
----- ------
2 2
5 6
欠番の始点と終点のペアが求められる美しい方法です。ちなみに Oracle は「start」を予約語にしているので、"start" と囲んで実行してください。
一方、答え5の結果も興味深いものです。
--答え5の結果:
seat rn available_seat_cnt
---- -- ------------------
3 2 1
4 3 1
7 4 3
rn 列は、座席番号順に連番を振っているだけです(rn は Row_Number の略です)。available_seat_cnt は、カレント行の座席番号未満の利用可能な席数です。例えば、3 と 4 の座席番号についてみれば、これより小さい空き番号は 2 だけなので、利用可能席数は 1、一方 座席番号 7 についみると、2, 5, 6 の三つが空いている、というわけです。
参考:
第10問 年金おくれよ
いま日本でも何かと話題の年金をテーマにとった問題。これがほんとの年金問題ですな。いや何でもないです。
えーさて、「直近」というのは SQL の集合指向的観点から考えると、最大下界のことです。これを表現するのはそれほど難しいことではありません。問題は、「連続」の方です。SQL はもともと行に順序を想定しないデータモデルを基礎に考えられているため、こういう連続や断絶の行間比較が難しかったのです(今では OLAP 関数の導入でかなり改善されています)。
テーブル定義は本文に掲載されているので、ここではサンプルデータを示します。
サンプルデータ
--○1番:1年間はたらかなった後、5年間フルにノ働いた
INSERT INTO Pensions VALUES('1', 2006, 12, 10);
INSERT INTO Pensions VALUES('1', 2005, 12, 10);
INSERT INTO Pensions VALUES('1', 2004, 12, 10);
INSERT INTO Pensions VALUES('1', 2003, 12, 10);
INSERT INTO Pensions VALUES('1', 2002, 12, 10);
INSERT INTO Pensions VALUES('1', 2001, 0, 0);
--○2番:10ヶ月 * 6年間
INSERT INTO Pensions VALUES('2', 2006, 10, 1);
INSERT INTO Pensions VALUES('2', 2005, 10, 1);
INSERT INTO Pensions VALUES('2', 2004, 10, 1);
INSERT INTO Pensions VALUES('2', 2003, 10, 1);
INSERT INTO Pensions VALUES('2', 2002, 10, 1);
INSERT INTO Pensions VALUES('2', 2001, 10, 1);
--×3番:10ヶ月 * 3年間, 1年休み, 10ヶ月 * 3
INSERT INTO Pensions VALUES('3', 2006, 10, 1);
INSERT INTO Pensions VALUES('3', 2005, 10, 1);
INSERT INTO Pensions VALUES('3', 2004, 10, 1);
INSERT INTO Pensions VALUES('3', 2003, 0, 0);
INSERT INTO Pensions VALUES('3', 2002, 10, 1);
INSERT INTO Pensions VALUES('3', 2001, 10, 1);
INSERT INTO Pensions VALUES('3', 2000, 10, 1);
--×4番:10ヶ月 * 1年間, 1年休み, 10ヶ月 * 5 + 9ヶ月
INSERT INTO Pensions VALUES('4', 2007, 9, 1);
INSERT INTO Pensions VALUES('4', 2006, 10, 1);
INSERT INTO Pensions VALUES('4', 2005, 10, 1);
INSERT INTO Pensions VALUES('4', 2004, 10, 1);
INSERT INTO Pensions VALUES('4', 2003, 10, 1);
INSERT INTO Pensions VALUES('4', 2002, 10, 1);
INSERT INTO Pensions VALUES('4', 2001, 0, 0);
INSERT INTO Pensions VALUES('4', 2000, 10, 1);
--○5番:10ヶ月 * 1年間, 1年休み, 10ヶ月 * 6
INSERT INTO Pensions VALUES('5', 2007, 10, 1);
INSERT INTO Pensions VALUES('5', 2006, 10, 1);
INSERT INTO Pensions VALUES('5', 2005, 10, 1);
INSERT INTO Pensions VALUES('5', 2004, 10, 1);
INSERT INTO Pensions VALUES('5', 2003, 10, 1);
INSERT INTO Pensions VALUES('5', 2002, 10, 1);
INSERT INTO Pensions VALUES('5', 2001, 0, 0);
INSERT INTO Pensions VALUES('5', 2000, 10, 1);
--×6番:12ヶ月 * 4年間, 1年休み
INSERT INTO Pensions VALUES('6', 2004, 0, 1);
INSERT INTO Pensions VALUES('6', 2003, 12, 1);
INSERT INTO Pensions VALUES('6', 2002, 12, 1);
INSERT INTO Pensions VALUES('6', 2001, 12, 0);
INSERT INTO Pensions VALUES('6', 2000, 12, 1);
--答え3用のビュー
CREATE VIEW PensionsView (sin, start_year, end_year, sumofearnings, sumofmonth_cnt)
AS SELECT PV0.sin,
PV0.pen_year AS start_year,
PV2.pen_year AS end_year,
SUM(PV1.earnings),
SUM(PV1.month_cnt)
FROM Pensions PV0, Pensions PV1, Pensions PV2
WHERE PV0.month_cnt > 0
AND PV1.month_cnt > 0
AND PV2.month_cnt > 0
AND PV0.sin = PV1.sin
AND PV0.sin = PV2.sin
AND PV0.pen_year BETWEEN PV2.pen_year-59 AND (PV2.pen_year - 4)
AND PV1.pen_year BETWEEN PV0.pen_year AND PV2.pen_year
GROUP BY PV0.sin, PV0.pen_year, PV2.pen_year
HAVING SUM(PV1.month_cnt) >= 60
AND (PV2.pen_year - PV0.pen_year) = (COUNT(*) - 1);
年金をもらう資格があるのは、1,2,5番の皆さん。1番は最短コースまっしぐらでゴール。2番は無理せずマイペース、5番は中休みを入れて、ともかく連続60ヶ月の労働をクリアしています。
一方、ものすごく惜しいのが4番の方。2007年にあと1ヶ月働けば受給資格をもらえたのに・・・まあまだ来年もあるのでがんばってください。
第11問 作業依頼
このパズルは名作! 集合指向の強みを縦横に駆使した最高のテクニックです。SQL を使っていて、この発想を理解しないのでは、DB エンジニアをやっている甲斐がない。そこまで言いましょう。本書の中で、これだけでも学んで帰ってください。
サンプルデータ
CREATE TABLE Projects
(workorder_id CHAR(5) NOT NULL,
step_nbr INTEGER NOT NULL
CHECK (step_nbr BETWEEN 0 AND 1000),
step_status CHAR(1) NOT NULL
CHECK (step_status IN ('C', 'W')), -- Cは完了、Wは待機
PRIMARY KEY (workorder_id, step_nbr));
INSERT INTO Projects VALUES('AA100', 0, 'C' );
INSERT INTO Projects VALUES('AA100', 1, 'W' );
INSERT INTO Projects VALUES('AA100', 2, 'W' );
INSERT INTO Projects VALUES('AA200', 0, 'W' );
INSERT INTO Projects VALUES('AA200', 1, 'W' );
INSERT INTO Projects VALUES('AA300', 0, 'C' );
INSERT INTO Projects VALUES('AA300', 1, 'C' );
答え2で実行してみると、次のようになります。
workorder_id
------------
AA100
HAVING 句が何をやっているかといえば、これは要するに全ての行について、条件に合致するかどうかを調べて、合致すれば 1、しなければ 0 というフラグを立てているのです。そして、フラグを数えた行数が、集合全体の行数と一致すれば、全ての行が条件を満たしていた、ということが分かるのです。
それでは、一つ別解を紹介しましょう。上の解が SQL の集合論的性格の表出だとすれば、以下に示すのは述語論理的性格のあらわれです。
--別解:述語論理の応用
SELECT DISTINCT workorder_id
FROM Projects P1
WHERE NOT EXISTS
(SELECT step_status
FROM Projects P2
WHERE P1.workorder_id = P2. workorder_id --プロジェクトごとに条件を調べる
AND step_status <> CASE WHEN step_nbr = 0 --全称文を二重否定で表現する
THEN 'C'
ELSE 'W' END);
workorder_id
------------
AA100
この問題の条件は全称量化文ですから、当然、こういう解法もあるわけです。workorder_id の主キーも使えるため、これは答え1,2に比べてかなり高速に動くでしょう。
参考:
第12問 訴訟の進行状況
ちょっと変わった要件の問題です。基本的には結合とサブクエリの練習と考えてください。テーブル定義がないので、実際に試してみたい方は以下のサンプルデータを活用してください。
サンプルデータ
CREATE TABLE Claims(
claim_id INTEGER,
patient_name VARCHAR(64),
PRIMARY KEY(claim_id));
CREATE TABLE Defendants(
claim_id INTEGER,
defendant_name VARCHAR(64),
PRIMARY KEY(claim_id, defendant_name));
CREATE TABLE LegalEvents(
claim_id INTEGER,
defendant_name VARCHAR(64),
claim_status CHAR(2),
change_date DATE,
PRIMARY KEY(claim_id, defendant_name, claim_status));
CREATE TABLE ClaimStatusCodes(
claim_status CHAR(2) PRIMARY KEY,
claim_status_desc VARCHAR(64),
claim_seq INTEGER);
INSERT INTO Claims VALUES( 10, 'Smith');
INSERT INTO Claims VALUES( 20, 'Jones');
INSERT INTO Claims VALUES( 30, 'Brown');
INSERT INTO Defendants VALUES (10, 'Johnson');
INSERT INTO Defendants VALUES (10, 'Meyer');
INSERT INTO Defendants VALUES (10, 'Dow');
INSERT INTO Defendants VALUES (20, 'Baker');
INSERT INTO Defendants VALUES (20, 'Meyer');
INSERT INTO Defendants VALUES (30, 'Johnson');
INSERT INTO LegalEvents VALUES(10, 'Johnson', 'AP', '1994-01-01' );
INSERT INTO LegalEvents VALUES(10, 'Johnson', 'OR', '1994-02-01' );
INSERT INTO LegalEvents VALUES(10, 'Johnson', 'SF', '1994-03-01' );
INSERT INTO LegalEvents VALUES(10, 'Johnson', 'CL', '1994-04-01' );
INSERT INTO LegalEvents VALUES(10, 'Meyer' , 'AP', '1994-01-01' );
INSERT INTO LegalEvents VALUES(10, 'Meyer' , 'OR', '1994-02-01' );
INSERT INTO LegalEvents VALUES(10, 'Meyer' , 'SF', '1994-03-01' );
INSERT INTO LegalEvents VALUES(10, 'Dow' , 'AP', '1994-01-01' );
INSERT INTO LegalEvents VALUES(10, 'Dow' , 'OR', '1994-02-01' );
INSERT INTO LegalEvents VALUES(20, 'Meyer' , 'AP', '1994-01-01' );
INSERT INTO LegalEvents VALUES(20, 'Meyer' , 'OR', '1994-02-01' );
INSERT INTO LegalEvents VALUES(20, 'Baker' , 'AP', '1994-01-01' );
INSERT INTO LegalEvents VALUES(30, 'Johnson', 'AP', '1994-01-01' );
INSERT INTO ClaimStatusCodes VALUES('AP', 'Awaiting review panel' , 1);
INSERT INTO ClaimStatusCodes VALUES('OR', 'Panel opinion rendered', 2);
INSERT INTO ClaimStatusCodes VALUES('SF', 'Suit filed' , 3);
INSERT INTO ClaimStatusCodes VALUES('CL', 'closed' , 4);
第13問 2 人かそれ以上か、それが問題だ
CASE 式の柔軟性が遺憾なく発揮されていてグッジョブ。実務でも、帳票に表示できる列数が固定されているということはよくあるもの。その点で大変実用的です。こういう表示のための整形はホスト言語でやるのも一つの正解ですが、SQL でやるならこれが定番。覚えておきましょう。
サンプルデータ
CREATE TABLE Register
(course_nbr INTEGER NOT NULL,
student_name CHAR(10) NOT NULL,
teacher_name CHAR(10) NOT NULL);
INSERT INTO Register VALUES(10, '生徒1', '先生1');
INSERT INTO Register VALUES(20, '生徒1', '先生1');
INSERT INTO Register VALUES(20, '生徒1', '先生2');
INSERT INTO Register VALUES(30, '生徒1', '先生1');
INSERT INTO Register VALUES(30, '生徒1', '先生2');
INSERT INTO Register VALUES(30, '生徒1', '先生3');
さて、サンプルデータの三つのコースのうち、10番と20番は、先生が二人以下なので別に問題ありません。問題は、30番のコースをどう料理するか、です。バカ正直に考えると答え1みたいに HAVING で条件を指定して UNION を使いたくなるかもしれませんが、それでは Smarty とは呼べません。「なるべくラクに、とにかく短く」が Smarty の流儀。その点、やはりレムレーは心得ています。ベスト・ソリューションは答え2です。
--答え2の結果
course_nbr student teacher_1 teacher_2
---------- -------- --------- ---------
10 生徒1 先生1
20 生徒1 先生1 先生2
30 生徒1 先生1 --More--
ちなみに、答え3の結果はこんなんです。
course_nbr student teacher
---------- ------- -------
10 生徒1 先生1
20 生徒1 先生1
先生2
30 生徒1 先生1
先生2
先生3
確かによく COBOL の出力帳票なんかで見かける、繰り返し項目を省いたレイアウトですね。繰り返すように、SQL でこういう見た目の整形までやるのは邪道ですが、でもまあ見事なものではあります。改めて CASE 式に惚れちゃいますね。
第14問 電話とFAX
この問題、私、最初ちょっと勘違いしていたんですが、電話というのは、あくまで自宅の電話、「いえ電」のことです。会社のデスクに置いてある内線じゃありません。「hom」ってのは「home」の略でしょう。Phones テーブルが電話についてのテーブルであるのに、電話番号を主キーにしていないのはそのためです。だって既婚社員は同じ番号を共有するから電話番号だけでは主キーにならないし、(社員ID, 電話番号)にしても、電話と FAX を同じ番号に設定している場合に重複してしまいます。内線なら電話番号だけで一意になるはずですものね。
サンプルデータ
CREATE TABLE Personnel
(emp_id INTEGER PRIMARY KEY,
first_name CHAR(20) NOT NULL,
last_name CHAR(20) NOT NULL);
CREATE TABLE Phones
(emp_id INTEGER NOT NULL,
phone_type CHAR(3) NOT NULL
CHECK (phone_type IN ('hom', 'fax')),
phone_nbr CHAR(12) NOT NULL,
PRIMARY KEY (emp_id, phone_type),
FOREIGN KEY (emp_id) REFERENCES Personnel(emp_id));
INSERT INTO Personnel VALUES(1, '山田', '太郎');
INSERT INTO Personnel VALUES(2, '上野', '二郎');
INSERT INTO Personnel VALUES(3, '高田', '三郎');
INSERT INTO Personnel VALUES(4, '松岡', '四郎');
INSERT INTO Phones VALUES(1, 'hom', 1111);
INSERT INTO Phones VALUES(1, 'fax', 2222);
INSERT INTO Phones VALUES(2, 'hom', 3333);
INSERT INTO Phones VALUES(3, 'fax', 4444);
電話しか持っていない上野さんは、FAX の列が NULL 、反対に FAX しか持っていない高田さん(どういう生活してるのだろう?)の電話列が NULL で現れます。骨子としては、極めてオーソドックスな外部結合の応用です。覚えておいて欲しいのは、答え4のスカラ・サブクエリの方法かな。
結果:
last_name first_name home_phone fax_phone
--------- ---------- ---------- ---------
太郎 山田 1111 2222
二郎 上野 3333
三郎 高田 4444
四郎 松岡
しかしまあ、この問題で完全外部結合使うのは大鉈振るいすぎです。
第15問 現在の給料と昇給前の給料
この問題には、ポイントが二つあります。一つは、いわゆる行列変換。これまでにも何度か出てきました。行持ちから列持ちへ展開するというアレです。もう一つが、極値関数の一般化、要するに「上位 n 位」までの出力です。
サンプルデータ
CREATE TABLE Salaries
(emp_name CHAR(10) NOT NULL,
sal_date DATE NOT NULL,
sal_amt DECIMAL (8,2) NOT NULL,
PRIMARY KEY (emp_name, sal_date));
INSERT INTO Salaries VALUES ('トム', '1996-06-20', 500.00);
INSERT INTO Salaries VALUES ('トム', '1996-08-20', 700.00);
INSERT INTO Salaries VALUES ('トム', '1996-10-20', 800.00);
INSERT INTO Salaries VALUES ('トム', '1996-12-20', 900.00);
INSERT INTO Salaries VALUES ('ディック', '1996-06-20', 500.00);
INSERT INTO Salaries VALUES ('ハリー','1996-07-20',500.00);
INSERT INTO Salaries VALUES ('ハリー', '1996-09-20', 700.00);
この問題に関しては、私は技術面以外でちょっと興味をそそられるところがありました。というのは、デイトやパスカルら原理主義的な理論家と、現場のエンジニアの苦しい立場に理解を示すセルコのスタンスの違いが、図らずも浮き彫りになっているからです。二人が「できっこないし、SQL でやることでもない」とそっぽを向いたのにカチンと来て、これでもかと執拗に別解を挙げていくあたり、かなり対抗心を燃やしているのが窺えます。
そりゃさ、理論的にはこんなこと SQL でやらない方がいいのは分かってるよ。でもだからって目の前の火事を放っとけっていうの? あんたたちは理想語ってりゃ済むかもしれないけど、現場はそんな綺麗事じゃ乗りきれんのよ。手が汚れるのを承知で、泥に手を突っ込まざるをえないときだってあるんだがや ―― 師の胸中を代弁すると、こんな感じでしょうか。直接訊いたわけじゃないから分からないけど、でもそんなに外してないと思います(デイトへの対抗心は21.飛行機と飛行士にも見え隠れする)。
第16問 主任とアシスタント
久々にテーブル定義の練習問題、特に外部キーの使い方に重点を置いています。やたらとテーブル定義のバージョンがあるので、どれを挙げようか(あるいは全部挙げるか)迷ったのですが、とりあえず完成形のものだけ示します。
サンプルデータ
CREATE TABLE Personnel
(emp_id INTEGER NOT NULL PRIMARY KEY,
emp_name CHAR(20) NOT NULL,
mech_type CHAR(10) NOT NULL
CHECK (mech_type IN ('Primary', 'Assistant')),
UNIQUE (emp_id, mech_type));
CREATE TABLE Jobs
(job_id INTEGER NOT NULL PRIMARY KEY REFERENCES Teams (job_id),
start_date DATE NOT NULL);
CREATE TABLE Teams
(job_id INTEGER NOT NULL REFERENCES Jobs(job_id),
primary_mech INTEGER NOT NULL,
primary_type CHAR(10) DEFAULT 'Primary' NOT NULL
CHECK (primary_type = 'Primary'),
assist_mech INTEGER NOT NULL ,
assist_type CHAR(10) DEFAULT 'Assistant' NOT NULL
CHECK (assist_type = 'Assistant') ,
CONSTRAINT fk_primary FOREIGN KEY (primary_mech, primary_type)
REFERENCES Personnel(emp_id, mech_type),
CONSTRAINT fk_assist FOREIGN KEY (assist_mech, assist_type)
REFERENCES Personnel(emp_id, mech_type),
CONSTRAINT at_least_one_mechanic
CHECK(COALESCE (primary_mech, assist_mech) IS NOT NULL)) ;
INSERT INTO Personnel VALUES(1, '赤木', 'Primary');
INSERT INTO Personnel VALUES(2, '伊藤', 'Assistant');
INSERT INTO Personnel VALUES(3, '宇佐美','Primary');
INSERT INTO Jobs VALUES(1, '2007-01-01');
INSERT INTO Jobs VALUES(2, '2007-02-01');
INSERT INTO Jobs VALUES(3, '2007-03-01');
INSERT INTO Jobs VALUES(4, '2007-04-01');
INSERT INTO Teams VALUES(1, 1, 'Primary', 2, 'Assistant');
INSERT INTO Teams VALUES(2, 3, 'Primary', 2, 'Assistant');
第17問 人材紹介会社
これはやや高度なテクニックを扱う問題です。しかし非常にエレガントかつ実用的で、ぜひ熟読玩味していただきたい。システム開発における問題とはこうやって解くものだ、という優れた見本です。
サンプルデータ
CREATE TABLE CandidateSkills
(candidate_id INTEGER NOT NULL,
skill_code CHAR(15) NOT NULL,
PRIMARY KEY (candidate_id, skill_code));
CREATE TABLE JobOrders
(job_id INTEGER NOT NULL,
skill_group INTEGER NOT NULL,
skill_code CHAR(15) NOT NULL,
PRIMARY KEY (job_id, skill_group, skill_code));
INSERT INTO CandidateSkills VALUES(100, '会計');
INSERT INTO CandidateSkills VALUES(100, '在庫管理');
INSERT INTO CandidateSkills VALUES(100, '製造');
INSERT INTO CandidateSkills VALUES(200, '会計');
INSERT INTO CandidateSkills VALUES(200, '在庫管理');
INSERT INTO CandidateSkills VALUES(300, '製造');
INSERT INTO CandidateSkills VALUES(400, '在庫管理');
INSERT INTO CandidateSkills VALUES(400, '製造');
INSERT INTO CandidateSkills VALUES(500, '会計');
INSERT INTO CandidateSkills VALUES(500, '製造');
INSERT INTO JobOrders VALUES(1, 1, '在庫管理');
INSERT INTO JobOrders VALUES(1, 1, '製造');
INSERT INTO JobOrders VALUES(1, 2, '会計');
INSERT INTO JobOrders VALUES(2, 1, '在庫管理');
INSERT INTO JobOrders VALUES(2, 1, '製造');
INSERT INTO JobOrders VALUES(2, 2, '会計');
INSERT INTO JobOrders VALUES(2, 2, '製造');
INSERT INTO JobOrders VALUES(3, 1, '製造');
INSERT INTO JobOrders VALUES(4, 1, '在庫管理');
INSERT INTO JobOrders VALUES(4, 1, '製造');
INSERT INTO JobOrders VALUES(4, 1, '会計');
それじゃためしに Job2 に適任な人材を検索してみましょう。条件は、「(在庫管理 かつ 製造) または ('会計' かつ '製造')」のスキルを持つ人物ですから、100、400、500の3名です。
--答え1
SELECT DISTINCT C1.candidate_id, 'job_id #2' -- 仕事IDコードの定数
FROM CandidateSkills C1, -- スキル1つにつき1テーブル
CandidateSkills C2,
CandidateSkills C3,
CandidateSkills C4
WHERE C1.candidate_id = C2.candidate_id
AND C1.candidate_id = C3.candidate_id
AND C1.candidate_id = C4.candidate_id
AND -- 以下で紹介依頼を表す式を作る
( ( C1.skill_code = '在庫管理'
AND C2.skill_code = '製造')
OR ( C3.skill_code = '会計'
AND C4.skill_code = '製造'));
candidate_id job_id#2
------------ ---------
100 job_id #2
400 job_id #2
500 job_id #2
スキルの入力が四つなので、テーブルも四つ用意しての自己結合。うーん、なるほど。確かにこれでも出来るのだけど、動的に SQL を作るのが難しいし、長くなるし(要求スキルが10個になったらどうすんだ)、自己結合はパフォーマンス面に不安を抱えます(10個どころか5個でも厳しい)。
そこで力を発揮するのが関係除算。
--答え2
SELECT DISTINCT J1.job_id, C1.candidate_id
FROM JobOrders J1 INNER JOIN CandidateSkills C1
ON J1.skill_code = C1.skill_code
GROUP BY candidate_id, skill_group, job_id
HAVING COUNT(*) >= (SELECT COUNT(*)
FROM JobOrders J2
WHERE J1.skill_group = J2.skill_group
AND J1.job_id = J2.job_id);
どうですかこの見事なソリューション。大学で論理学の講義を受けた人は、標準形について習ったと思いますが、こんな実践的な活かし方があるんです。何が役に立つ知識かは、役に立たせようとする意志の有無によっても左右を受けるってことですね。
ところで、最近の日本でも派遣会社が隆盛を見ているので、この問題がドンピシャリ当てはまる要件も多そうな気がしますが、派遣会社のシステム担当の方、どうでしょう?
第18問 ダイレクトメール
これも7.ファイルのバージョン管理と同様、ポインタ・チェインの構造をそのままテーブルにしてしまったがゆえに生じた問題の尻拭いです。一番悪いのは、こんなテーブル構造にした設計者です。本当なら家族のメンバーは別テーブルに外出しにするべきでしょう。
サンプルデータ
CREATE TABLE Consumers
(conname VARCHAR(64),
address VARCHAR(64),
con_id INTEGER,
fam INTEGER);
INSERT INTO Consumers VALUES('ボブ', 'A', 1, NULL );
INSERT INTO Consumers VALUES('ジョー', 'B', 3, NULL );
INSERT INTO Consumers VALUES('マーク' , 'C', 5, NULL );
INSERT INTO Consumers VALUES('メアリー', 'A', 2, 1 );
INSERT INTO Consumers VALUES('ヴィッキー', 'B', 4, 3 );
INSERT INTO Consumers VALUES('ウェイン', 'D', 6, NULL );
実行後の結果は次のようになります。
conname addres con_id fam
--------- ------- ------ ----
マーク C 5
メアリー A 2 1
ヴィッキー B 4 3
ウェイン D 6
技術的な見所としては、DELETE 文で相関サブクエリを使うところです。注意が必要なのは、「DELETE FROM Consumers AS C1」のように相関名を付けることが、文法上許されていないことです(中には許す DB もあるけど、汎用的ではない)。だから、全ての答えにおいて「Consumers」というテーブル名をそのまま使っています。
第19問 セールスマンの売上ランキング
極値関数の一般化問題です。パズル15より先にこっちを先にもってきた方が理解しやすいんじゃないかと個人的には思います
サンプルデータ
CREATE TABLE SalesData
(district_nbr INTEGER NOT NULL,
sales_person CHAR(10) NOT NULL,
sales_id INTEGER NOT NULL,
sales_amt DECIMAL(5,2) NOT NULL);
INSERT INTO SalesData VALUES(1, 'カーリー' , 5, 3.00 );
INSERT INTO SalesData VALUES(1, 'ハーポ' , 11, 4.00 );
INSERT INTO SalesData VALUES(1, 'ラリー' , 1, 50.00 );
INSERT INTO SalesData VALUES(1, 'ラリー' , 2, 50.00 );
INSERT INTO SalesData VALUES(1, 'ラリー' , 3, 50.00 );
INSERT INTO SalesData VALUES(1, 'モー' , 4, 5.00 );
INSERT INTO SalesData VALUES(2, 'ディック' , 8, 5.00 );
INSERT INTO SalesData VALUES(2, 'フレッド' , 7, 5.00 );
INSERT INTO SalesData VALUES(2, 'ハリー' , 6, 5.00 );
INSERT INTO SalesData VALUES(2, 'トム' , 7, 5.00 );
INSERT INTO SalesData VALUES(3, 'アーヴィン' , 10, 5.00 );
INSERT INTO SalesData VALUES(3, 'メルヴィン' , 9, 7.00 );
INSERT INTO SalesData VALUES(4, 'ジェニー' , 15, 20.00 );
INSERT INTO SalesData VALUES(4, 'ジェシー' , 16, 10.00 );
INSERT INTO SalesData VALUES(4, 'メアリー' , 12, 50.00 );
INSERT INTO SalesData VALUES(4, 'オプラ' , 14, 30.00 );
INSERT INTO SalesData VALUES(4, 'サリー' , 13, 40.00 );
使える環境さえあれば、答え2の OLAP 関数を使うのがよいでしょう。使えないと自己結合で再帰集合を作ることになります。
第20問 テスト結果
もう数年前のことですが、私はこの問題の意味を初めて理解したとき、体が震えました。「ああ、SQL といふのは一個の藝術であったか」と意味不明の言葉を口走り、震える手でページを捲ったことを今でも覚えています。思わずたわ言が口をついて出ちゃうぐらい、この問題の解法は凄いのです。
サンプルデータ
CREATE TABLE TestResults
(test_name CHAR(20) NOT NULL,
test_step INTEGER NOT NULL,
comp_date DATE, -- NULLは未完了を意味する
PRIMARY KEY (test_name, test_step));
INSERT INTO TestResults VALUES('読解', 1, '2006-03-10');
INSERT INTO TestResults VALUES('読解', 2, '2006-03-12');
INSERT INTO TestResults VALUES('数学', 1, NULL);
INSERT INTO TestResults VALUES('数学', 2, '2006-03-12');
INSERT INTO TestResults VALUES('化学', 1, '2006-03-08');
INSERT INTO TestResults VALUES('化学', 2, '2006-03-12');
INSERT INTO TestResults VALUES('化学', 3, '2006-03-15');
上のサンプルにおいて、全てのテストが終了している科目は「読解」と「化学」。これを選択するのが目標です。
答え2がなぜうまく行くかといえば、COUNT(列名)が NULL を除外して集計するからですね。だから、COUNT(*) と件数が一致するのは、当該の集合が NULL を含まなかった場合だけです。
これは全称量化の一応用例ですので、より一般的には CASE 式で特性関数を作ることによって表現できます。同じことをやるなら次のとおり。
--答え2:CASE式版
SELECT test_name
FROM TestResults
GROUP BY test_name
HAVING COUNT(*) = SUM(CASE WHEN comp_date IS NOT NULL
THEN 1
ELSE 0 END);
これでも結果は同じです。この問題は集合の図を描いてみた方が理解しやすいので、より深く知りたい方はリンク先の記事を参照してください。
参考:
第21問 飛行機と飛行士
関係除算というのは、重要な割に知名度の低い演算で、そのため私はことあるたびに関係除算の宣伝をしています。実は、本書でもこの演算はキーポイントの一つで、陰に陽にあちこちの問題で応用されています。
サンプルデータ
CREATE TABLE PilotSkills
(pilot CHAR(15) NOT NULL,
plane CHAR(15) NOT NULL,
PRIMARY KEY (pilot, plane));
CREATE TABLE Hangar
(plane CHAR(15) PRIMARY KEY);
INSERT INTO PilotSkills VALUES ('Celko', 'Piper Cub');
INSERT INTO PilotSkills VALUES ('Higgins', 'B-52 Bomber');
INSERT INTO PilotSkills VALUES ('Higgins', 'F-14 Fighter');
INSERT INTO PilotSkills VALUES ('Higgins', 'Piper Cub');
INSERT INTO PilotSkills VALUES ('Jones', 'B-52 Bomber');
INSERT INTO PilotSkills VALUES ('Jones', 'F-14 Bomber');
INSERT INTO PilotSkills VALUES ('Smith', 'B-1 Bomber');
INSERT INTO PilotSkills VALUES ('Smith', 'B-52 Bomber');
INSERT INTO PilotSkills VALUES ('Smith', 'F-14 Fighter');
INSERT INTO PilotSkills VALUES ('Wilson', 'B-1 Bomber');
INSERT INTO PilotSkills VALUES ('Wilson', 'B-52 Bomber');
INSERT INTO PilotSkills VALUES ('Wilson', 'F-14 Fighter');
INSERT INTO PilotSkills VALUES ('Wilson', 'F-17 Fighter');
INSERT INTO Hangar VALUES ('B-1 Bomber');
INSERT INTO Hangar VALUES ('B-52 Bomber');
INSERT INTO Hangar VALUES ('F-14 Fighter');
関係除算とは、この問題に即して言えば「格納庫に存在する全ての機体を操縦できるパイロットを探す」です。これは、形を変えて色んな状況で現れる要件です。
ここでは、EXCEPT 演算子を用いた別解を紹介しましょう。
--関係除算:減算に還元して解く
SELECT DISTINCT pilot
FROM PilotSkills PS1
WHERE NOT EXISTS
(SELECT plane
FROM Hangar
EXCEPT
SELECT plane
FROM PilotSkills PS2
WHERE PS1.pilot = PS2.pilot);
pilot
-------
Smith
Wilson
これも仕組みを追うと興味深い点が多いのですが、詳しい解説は次の参考資料を参照してください。
参考:
第22問 大家の悩み
テーブル定義もサンプルデータもないのが不親切ですね。テーブル定義は書籍本文にも載せましたが、ここでは一応サンプルも示しておきましょう。サンプルは適当に組み替えて試してみてください。
サンプルデータ
CREATE TABLE Tenants
(tenant_id INTEGER,
unit_nbr INTEGER,
vacated_date DATE,
PRIMARY KEY (tenant_id, unit_nbr));
CREATE TABLE Units
(complex_id INTEGER,
unit_nbr INTEGER,
PRIMARY KEY (complex_id, unit_nbr));
CREATE TABLE RentPayments
(tenant_id INTEGER,
unit_nbr INTEGER,
payment_date DATE,
PRIMARY KEY (tenant_id, unit_nbr));
--サンプルデータ
INSERT INTO Tenants VALUES(1, 1, NULL);
INSERT INTO Tenants VALUES(1, 2, NULL);
INSERT INTO Tenants VALUES(1, 3, '2007-01-01');
INSERT INTO Units VALUES(32, 1);
INSERT INTO Units VALUES(32, 2);
INSERT INTO Units VALUES(32, 3);
/* ユニット1は家賃を払っている。2は払っていない */
INSERT INTO RentPayments VALUES(1, 1, '2007-03-01');
第23問 雑誌と売店
AND や OR を組み合わせたこういう複雑な条件での検索は、データウェアハウス業務に典型的な仕様です。これをまともに SQL へ直訳しようとすると、答え1みたいに WHERE 句や HAVING 句に長々と条件を連ねることになります。これはコードが長大になって読みにくいし、パフォーマンスも悪化します。こんなとき頼りになるのは、やっぱり CASE 式です。答え4,5,7などは、是非お手本にしてほしい見事な解答です。特に答え5は素晴らしい。簡潔で読みやすく、かつソートもGROUP BYによる一度だけなのでパフォーマンスも上々です。
サンプルデータ
CREATE TABLE Titles
(product_id INTEGER NOT NULL PRIMARY KEY,
magazine_sku INTEGER NOT NULL,
issn INTEGER NOT NULL,
issn_year INTEGER NOT NULL);
CREATE TABLE Newsstands
(stand_nbr INTEGER NOT NULL PRIMARY KEY,
stand_name CHAR(20) NOT NULL);
CREATE TABLE Sales
(product_id INTEGER NOT NULL REFERENCES Titles(product_id),
stand_nbr INTEGER NOT NULL REFERENCES Newsstands(stand_nbr),
net_sold_qty INTEGER NOT NULL,
PRIMARY KEY(product_id, stand_nbr));
INSERT INTO Titles VALUES(1, 12345, 1, 2006);
INSERT INTO Titles VALUES(2, 2667, 1, 2006);
INSERT INTO Titles VALUES(3, 48632, 1, 2006);
INSERT INTO Titles VALUES(4, 1107, 1, 2006);
INSERT INTO Titles VALUES(5, 12345, 2, 2006);
INSERT INTO Titles VALUES(6, 2667, 2, 2006);
INSERT INTO Titles VALUES(7, 48632, 2, 2006);
INSERT INTO Titles VALUES(8, 1107, 2, 2006);
INSERT INTO Newsstands VALUES(1, 'Newsstands1');
INSERT INTO Newsstands VALUES(2, 'Newsstands2');
INSERT INTO Newsstands VALUES(3, 'Newsstands3');
INSERT INTO Newsstands VALUES(4, 'Newsstands4');
INSERT INTO Sales VALUES(1, 1, 1);
INSERT INTO Sales VALUES(2, 1, 4);
INSERT INTO Sales VALUES(3, 1, 1);
INSERT INTO Sales VALUES(4, 1, 1);
INSERT INTO Sales VALUES(5, 1, 1);
INSERT INTO Sales VALUES(6, 1, 2);
INSERT INTO Sales VALUES(7, 1, 1);
INSERT INTO Sales VALUES(3, 2, 1);
INSERT INTO Sales VALUES(4, 2, 5);
INSERT INTO Sales VALUES(8, 2, 6);
INSERT INTO Sales VALUES(1, 3, 1);
INSERT INTO Sales VALUES(2, 3, 3);
INSERT INTO Sales VALUES(3, 3, 3);
INSERT INTO Sales VALUES(4, 3, 1);
INSERT INTO Sales VALUES(5, 3, 1);
INSERT INTO Sales VALUES(6, 3, 3);
INSERT INTO Sales VALUES(7, 3, 3);
INSERT INTO Sales VALUES(1, 4, 1);
INSERT INTO Sales VALUES(2, 4, 1);
INSERT INTO Sales VALUES(3, 4, 4);
INSERT INTO Sales VALUES(4, 4, 1);
INSERT INTO Sales VALUES(5, 4, 1);
INSERT INTO Sales VALUES(6, 4, 1);
INSERT INTO Sales VALUES(7, 4, 2);
選択されるのは売店2と3です。なお、答え7は売店番号を求めるにとどめているので、売店名が知りたい場合はこの結果と結合します。練習にやってみてください。
第24問 10 個のうち1 つだけ
この手のテーブルを見ると、私たち DB エンジニアは「ああ、またか……」と溜息をつきます。何の考えもなしに配列をテーブルに移しとると、こんなげんなりする設計になります。
配列は、要素数をかなり柔軟に増減させることができますが、テーブルの列はそうではありません。1列増減するだけでもけっこうな大事です。一方、行の増減はプログラムの構造に何の影響も及ぼしません。このことから、データベースのテーブル設計においては、列はある程度持続的な構造として考えるべきであるという原則が導かれます。列に頻繁に変更が生じる場合は、行持ちにすることを考えるべきです。そもそも、テーブルを配列になぞらえて考える開発者は、テーブルが現実世界の実体(エンティティ)を写像した存在であるという関係モデルの基礎理論に無自覚です。そういう視点を持っている人なら、絶対にこんな設計にはしません。最近は配列型をサポートする実装も出てきましたが、まだこれを利用する方が筋が通ります。
しかしま、世の中の現場が常に厳正な規則に従って運営されているかといえばさにあらず。むしろこのパズルみたいに安直なケースが大多数でしょう。かくして DB エンジニアの悩みの種は尽きることがないのです。
サンプルデータ
CREATE TABLE MyTable
(keycol INTEGER NOT NULL,
f1 INTEGER NOT NULL,
f2 INTEGER NOT NULL,
f3 INTEGER NOT NULL,
f4 INTEGER NOT NULL,
f5 INTEGER NOT NULL,
f6 INTEGER NOT NULL,
f7 INTEGER NOT NULL,
f8 INTEGER NOT NULL,
f9 INTEGER NOT NULL,
f10 INTEGER NOT NULL);
--選択対象
INSERT INTO MyTable VALUES(333, 0, -1, 0, 0, 0, 0, 0, 0, 0, 0);
INSERT INTO MyTable VALUES(444, 0, 0, 0, 0, 0, 0, 0, 0, 0, 9);
INSERT INTO MyTable VALUES(999, 0, 0, 0, 0, 6, 0, 0, 0, 0, 0);
--選択対象外
INSERT INTO MyTable VALUES(555, 1, -1, 0, 0, 0, 0, 0, 0, 0, 0);
INSERT INTO MyTable VALUES(666, 1, 2, 3, 0, 0, 0, 0, 0, 0, 0);
INSERT INTO MyTable VALUES(777, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0);
すいません、愚痴が長くなりました。いつまでもクダ巻いていても始まらないので、テーブルが汚いなら汚いなりに、何とか次善の策を工夫して乗り切りましょう。そんなわけで、このパズルに登場するコードは、実用的といえば実用的ではあるのです(一番いいのは、もちろん答え2のように行持ちにすることですけど)。
ここでは、途中で省略されている答え3と4のコードを示します。行構築子を使っていますが、別にこれを使わなくても書けますし、その方が通る実装も増えるでしょう。
SELECT *
FROM MyTable
WHERE (f1, f2, f3, f4, f5, f6, f7, f8, f9, f10) IN
((f1, 0, 0, 0, 0, 0, 0, 0, 0, 0),
(0, f2, 0, 0, 0, 0, 0, 0, 0, 0),
(0, 0, f3, 0, 0, 0, 0, 0, 0, 0),
(0, 0, 0, f4, 0, 0, 0, 0, 0, 0),
(0, 0, 0, 0, f5, 0, 0, 0, 0, 0),
(0, 0, 0, 0, 0, f6, 0, 0, 0, 0),
(0, 0, 0, 0, 0, 0, f7, 0, 0, 0),
(0, 0, 0, 0, 0, 0, 0, f8, 0, 0),
(0, 0, 0, 0, 0, 0, 0, 0, f9, 0),
(0, 0, 0, 0, 0, 0, 0, 0, 0, f10))
AND (f1 + f2 + f3 + f4 + f5 + f6 + f7 + f8 + f9 + f10) <> 0;
--答え#4
SELECT *
FROM MyTable
WHERE 0 IN ((f2 + f3 + f4 + f5 + f6 + f7 + f8 + f9 + f10),
(f1 + f3 + f4 + f5 + f6 + f7 + f8 + f9 + f10),
(f1 + f2 + f4 + f5 + f6 + f7 + f8 + f9 + f10),
(f1 + f2 + f3 + f5 + f6 + f7 + f8 + f9 + f10),
(f1 + f2 + f3 + f4 + f6 + f7 + f8 + f9 + f10),
(f1 + f2 + f3 + f4 + f5 + f7 + f8 + f9 + f10),
(f1 + f2 + f3 + f4 + f5 + f6 + f8 + f9 + f10),
(f1 + f2 + f3 + f4 + f5 + f6 + f7 + f9 + f10),
(f1 + f2 + f3 + f4 + f5 + f6 + f7 + f8 + f10),
(f1 + f2 + f3 + f4 + f5 + f6 + f7 + f8 + f9))
AND (f1 + f2 + f3 + f4 + f5 + f6 + f7 + f8 + f9 + f10) <> 0;
keycol f1 f2 f3 f4 f5 f6 f7 f8 f9 f10
------ -- -- -- -- -- -- -- -- -- ---
333 0 -1 0 0 0 0 0 0 0 0
444 0 0 0 0 0 0 0 0 0 9
999 0 0 0 0 6 0 0 0 0 0
この問題でもう一つ注目すべきことは、答え5で紹介されている、COALESCE(「こありーす」とか「こうあれす」と発音します)の使い方です。聞きなれない単語ですが、意味は「結合する、癒着する」。これは全ての実装で利用できる標準関数で、使いこなすと非常に便利なのですが、いまいち有名ではありません(私は読みと綴りの難しさがその一因だと踏んでいる)。機能としては、NULL を値に変換するもの、と思ってください。Oracle ユーザなら NVL に喩えるのが分かりやすいでしょう。
しかし、NVL と COALESCE には大きな違いがあります。それは、COALESCE が可変個の引数を取れることです。現実的には実装によって上限数は決まっていますが、それを超えるほどの引数を渡す必要が生じることはまれでしょう。しかし、この柔軟性の高さから、かなり幅広い応用が可能なのです。
参考:
第25問 マイルストーン
またまた登場の行列変換問題です。それだけ実務でもネックになることが多いのでしょう。私も仕事でしょっちゅうやってます。
サンプルデータ
CREATE TABLE ServicesSchedule
(shop_id CHAR(3) NOT NULL,
order_nbr CHAR(10) NOT NULL,
sch_seq INTEGER NOT NULL CHECK (sch_seq IN (1,2,3)),
service_type CHAR(2) NOT NULL,
sch_date DATE,
PRIMARY KEY (shop_id, order_nbr, sch_seq));
INSERT INTO ServicesSchedule VALUES('002', '4155526710', 1, '01', '1994-07-16' );
INSERT INTO ServicesSchedule VALUES('002', '4155526710', 2, '01', '1994-07-30' );
INSERT INTO ServicesSchedule VALUES('002', '4155526710', 3, '01', '1994-10-01' );
INSERT INTO ServicesSchedule VALUES('002', '4155526711', 1, '01', '1994-07-16' );
INSERT INTO ServicesSchedule VALUES('002', '4155526711', 2, '01', '1994-07-30' );
INSERT INTO ServicesSchedule VALUES('002', '4155526711', 3, '01', NULL );
SQL で行から列への水平展開を行う方法は数多く存在しますが、ここにはそれらがほとんど全て網羅されていると言っていいでしょう。私のお気に入りは、スカラ・サブクエリを使う答え2と、CASE 式を使う答え4です。どちらも列の増減といった仕様変更に強い柔軟なコードです。
結果:
order_nbr processed completed confirmed
---------- -------- -------- --------
4155526710 94-07-16 94-07-30 94-10-01
皆さんもぜひ、行列変換の技術は身につけてください。絶対に損しませんから。
第26問 DFD
ちょっと変わった問題。一言で言うと「本当はテーブルに存在しなくてはいけないのに、実際には存在していないデータ」を調査するものです。入力データが汚くて、クリーニングが必要な場合などに有用な技術です。
サンプルデータ
CREATE TABLE DataFlowDiagrams
(diagram_name CHAR(10) NOT NULL,
bubble_name CHAR(10) NOT NULL,
flow_name CHAR(10) NOT NULL,
PRIMARY KEY (diagram_name, bubble_name, flow_name));
INSERT INTO DataFlowDiagrams VALUES('Proc1', 'input' , 'guesses');
INSERT INTO DataFlowDiagrams VALUES('Proc1', 'input' , 'opinions');
INSERT INTO DataFlowDiagrams VALUES('Proc1', 'crunch', 'facts');
INSERT INTO DataFlowDiagrams VALUES('Proc1', 'crunch', 'guesses');
INSERT INTO DataFlowDiagrams VALUES('Proc1', 'crunch', 'opinions' );
INSERT INTO DataFlowDiagrams VALUES('Proc1', 'output', 'facts');
INSERT INTO DataFlowDiagrams VALUES('Proc1', 'output', 'guesses');
INSERT INTO DataFlowDiagrams VALUES('Proc2', 'reckon', 'guesses');
INSERT INTO DataFlowDiagrams VALUES('Proc2', 'reckon', 'opinions' );
一つのバブルに対して、入力となるフローは本来、('guesses', 'opinions', 'facts')の三つ存在しなければなりません。しかし実際にはこのテーブルは不完全で欠けているフローがあるわけです。
答え1〜3とも、「完全な組み合わせをつくり、実際の組み合わせを引く」という基本的な考え方は一緒です。引き算に集合演算子を使うか NOT IN や NOT EXISTS を使うかの違いがあるだけです。
結果:
diagram bubble flow
------- ------ --------
Proc1 input facts
Proc1 output opinions
Proc2 reckon facts
なお、DB2 のように CROSS JOIN 構文を持っていない実装では、「DataFlowDiagrams F1, DataFlowDiagrams F2」というカンマでテーブルを区切って並べる古い書式を使う必要があります。大抵の DB では問題なく使えると思いますが。
参考:
第27問 等しい集合を見つける
本文にも書かれていますが、これはデータベースの世界では非常に有名な古典的問題です。古典というだけあって、SQL のロジックの核心に関わります。また、その解法を学ぶことから非常に多くのことが得られるという点でも、古典と呼ぶにふさわしい。
サンプルデータ
CREATE TABLE SupParts
(sno INTEGER NOT NULL,
pno INTEGER NOT NULL,
PRIMARY KEY (sno, pno));
--1と3、2と4が一致する
INSERT INTO SupParts VALUES(1, 01);
INSERT INTO SupParts VALUES(1, 02);
INSERT INTO SupParts VALUES(1, 03);
INSERT INTO SupParts VALUES(2, 01);
INSERT INTO SupParts VALUES(2, 03);
INSERT INTO SupParts VALUES(3, 01);
INSERT INTO SupParts VALUES(3, 02);
INSERT INTO SupParts VALUES(3, 03);
INSERT INTO SupParts VALUES(4, 01);
INSERT INTO SupParts VALUES(4, 03);
INSERT INTO SupParts VALUES(5, 05);
INSERT INTO SupParts VALUES(6, 01);
INSERT INTO SupParts VALUES(6, 02);
--答え8用
CREATE TABLE Tbl_A
(key INTEGER PRIMARY KEY,
col1 INTEGER ,
col2 INTEGER,
col3 INTEGER);
CREATE TABLE Tbl_B
(key INTEGER PRIMARY KEY,
col1 INTEGER,
col2 INTEGER,
col3 INTEGER);
INSERT INTO Tbl_A VALUES(1, 2, 3, 4);
INSERT INTO Tbl_A VALUES(2, 0, 0, NULL);
INSERT INTO Tbl_A VALUES(3, 1, 1, 1);
INSERT INTO Tbl_B VALUES(1, 2, 3, 4);
INSERT INTO Tbl_B VALUES(2, 0, 0, 0);
INSERT INTO Tbl_B VALUES(3, 1, 1, 1);
結果は次のようになります。
sno sno
--- ---
1 3
2 4
答え3などのWHERE句の最初の条件「SP1.sno < SP2.sno」は、業者の組み合わせを作っています。非等値結合で組み合わせを作るこの技術は、44.商品のペアでも活用されています。詳しい動作は以下の参考資料を参照。
参考:
第28問 正弦関数を作る
sine関数をネタに内挿法を勉強しようという数学パズルです。
サンプルデータ
CREATE TABLE Sine
(x REAL NOT NULL,
sin REAL NOT NULL);
INSERT INTO Sine VALUES (0.00, 0.0000);
INSERT INTO Sine VALUES (0.75, 0.6816);
INSERT INTO Sine VALUES (0.76, 0.6889);
INSERT INTO Sine VALUES (1.00, 1.0000);
リンク先のグラフを見てもらえば分かるように、sine 関数は曲線を描きます。従って、正式な sine 関数の公式によらず値を計算すれば、どうやっても近似値にしかなりません。それをなるべく正確な数値に近づけよう、という趣旨です。
セルコが答え2で「SQLらしい」解法として提案しているのは、計算ではなくテーブル検索によって近似値を発見する方法です。これを彼は「テーブル駆動型(table-drive)」の解法と名づけています。
参考:
第29問 最頻値を求める
最頻値というのは、ある集団の中央の値を代表する統計指標の一つで、集団内で最も数の多かった値のことです(その点で「流行値」という名前の方がイメージが湧きやすいかも)。一般的には集団の中央の値というと、平均がメジャーですが、平均は外れ値に影響を受けやすいという弱点を持っています。そういうとき、代わりに利用されるのがこの指標です。
サンプルデータ
CREATE TABLE Payroll
(check_nbr INTEGER NOT NULL PRIMARY KEY,
check_amt DECIMAL(8,2) NOT NULL);
INSERT INTO Payroll VALUES(1, 100);
INSERT INTO Payroll VALUES(2, 100);
INSERT INTO Payroll VALUES(3, 200);
INSERT INTO Payroll VALUES(4, 150);
INSERT INTO Payroll VALUES(5, 300);
INSERT INTO Payroll VALUES(6, 150);
INSERT INTO Payroll VALUES(7, 300);
INSERT INTO Payroll VALUES(8, 300);
INSERT INTO Payroll VALUES(9, 100);
上のサンプルを使って考えるなら、最頻値は 100 と 300 です。このように、最頻値は一つの集団内で複数存在することがあります(二つある場合は二峰分布と言います)。
結果:
check_amt check_cnt
--------- ---------
100 3
300 3
答え1〜3ともに、最頻値が複数ある場合はそれらを全て網羅します。chck_cnt は、その値の個数です。これも同時に得られると便利ですね。
参考:
第30問 買い物の平均サイクル
日付データの扱い方、特に二点間の間隔の求め方がテーマの問題です。その意味では、日付に限らず数値型のデータを使う場合にも応用がききます。
サンプルデータ
CREATE TABLE Sales
(customer_name CHAR(5) NOT NULL,
sale_date DATE NOT NULL,
PRIMARY KEY (customer_name, sale_date));
INSERT INTO Sales VALUES('Fred', '1994-06-01');
INSERT INTO Sales VALUES('Mary', '1994-06-01');
INSERT INTO Sales VALUES('Bill', '1994-06-01');
INSERT INTO Sales VALUES('Fred', '1994-06-02');
INSERT INTO Sales VALUES('Bill', '1994-06-02');
INSERT INTO Sales VALUES('Bill', '1994-06-03');
INSERT INTO Sales VALUES('Bill', '1994-06-04');
INSERT INTO Sales VALUES('Bill', '1994-06-05');
INSERT INTO Sales VALUES('Bill', '1994-06-06');
INSERT INTO Sales VALUES('Bill', '1994-06-07');
INSERT INTO Sales VALUES('Fred', '1994-06-07');
INSERT INTO Sales VALUES('Mary', '1994-06-08');
解答は二つ紹介されていますが、ロジックとして面白いのは答えその1です。というのも、この最大下界を求めるクエリは、実はパズル35でも使う同心円的な再帰集合を作っているからです。
例えば、Bill をサンプルに見れば、答えその1のスカラ・サブクエリは、カレント行(S1)よりも前の日付の集合(S2)、いわば下界集合を作るわけですから、次のような入れ子状の再帰集合になります。
-- Bill について見た場合の下界集合
S0 (1994-06-01): Ø
S1 (1994-06-02): { 1994-06-01 }
S2 (1994-06-03): { 1994-06-01, 1994-06-02 }
S3 (1994-06-04): { 1994-06-01, 1994-06-02, 1994-06-03 }
・
・
6月1日より前の日付は、テーブルに存在しないので、これをキーにするのは空集合(スカラ・サブクエリはこれを NULL で表現しています)、6月2日より前の日付は6月1日だけ、6月3日の場合は 6月1日, 6月2日の二つ …… と、同じ要領で作ります。こうしてできあがったピラミッド状の各集合から、MAX 関数を使って最大値を取得すれば、各日付ごとの直近が求まる、という寸法です。
Oracle なら、スカラ・サブクエリを LAG 関数で置き換る次のような解も考えられます。
-- OLAP 関数で直近の日付を求める
SELECT customer_name, sale_date,
LAG(sale_date, 1) OVER(PARTITION BY customer_name
ORDER BY sale_date) AS latest_date
FROM Sales ;
なかなか簡潔ですし、自己結合も要りません。LAG を持たない他の DB でもちょっと工夫すれば標準的な OLAP 関数で求められます。これは練習にしておきましょう。
なお、この問題では DAYS 関数を使っていますが、訳注にも書いたように、Oracle や PostgreSQL では直接、日付の引き算をすることができます。SQLServer と MS-Access では、DATEDIFF 関数を使います。
参考:
第31問 すべての製品を購入した顧客
問題文に「すべての」とか「いくつかの」という言葉があることからして、これが全称量化と存在量化を扱う問題であることは即座に知れます。そして、SQL で全称量化を記述する方法は、NOT EXISTS 述語と集約関数の二通りがあります。従って、解答もこのどちらかを使うことになります。「伝統的」と言われている答え1が前者、答え2が後者です。答え3は、まあ答え2の応用版です。
ただ、この問題でちょっと変わっているのは、「少なくとも一つの製品」を買った客を求めるときに、「全て買った客は除外する」という条件が追加されることです(些細な点ですが)。
サンプルデータ
CREATE TABLE Customers
(customer_id INTEGER NOT NULL PRIMARY KEY,
acct_balance DECIMAL (12, 2) NOT NULL);
CREATE TABLE Orders
(customer_id INTEGER NOT NULL,
order_id INTEGER NOT NULL PRIMARY KEY);
CREATE TABLE OrderDetails
(order_id INTEGER NOT NULL,
item_id INTEGER NOT NULL,
item_qty INTEGER NOT NULL,
PRIMARY KEY(order_id, item_id));
CREATE TABLE Products
(item_id INTEGER NOT NULL PRIMARY KEY,
item_qty_on_hand INTEGER NOT NULL);
--顧客1と2は全部の製品を買っている。顧客bRと4は一部の製品だけ買っている。顧客5と6は一つも注文していない。
DELETE FROM Customers;
INSERT INTO Customers VALUES(1, 10);
INSERT INTO Customers VALUES(2, 20);
INSERT INTO Customers VALUES(3, 30);
INSERT INTO Customers VALUES(4, 40);
INSERT INTO Customers VALUES(5, 50);
INSERT INTO Customers VALUES(6, 60);
--注文テーブル
DELETE FROM Orders;
INSERT INTO Orders VALUES(1, 1);
INSERT INTO Orders VALUES(1, 2);
INSERT INTO Orders VALUES(2, 3);
INSERT INTO Orders VALUES(3, 4);
INSERT INTO Orders VALUES(3, 5);
INSERT INTO Orders VALUES(3, 6);
INSERT INTO Orders VALUES(4, 7);
--注文明細テーブル
DELETE FROM OrderDetails;
INSERT INTO OrderDetails VALUES(1, 1, 1);
INSERT INTO OrderDetails VALUES(2, 1, 1);
INSERT INTO OrderDetails VALUES(2, 2, 1);
INSERT INTO OrderDetails VALUES(2, 3, 1);
INSERT INTO OrderDetails VALUES(3, 1, 1);
INSERT INTO OrderDetails VALUES(3, 2, 1);
INSERT INTO OrderDetails VALUES(3, 3, 1);
INSERT INTO OrderDetails VALUES(4, 1, 1);
INSERT INTO OrderDetails VALUES(5, 1, 1);
INSERT INTO OrderDetails VALUES(6, 1, 1);
INSERT INTO OrderDetails VALUES(7, 1, 1);
--製品テーブル
DELETE FROM Products;
INSERT INTO Products VALUES(1, 1);
INSERT INTO Products VALUES(2, 1);
INSERT INTO Products VALUES(3, 1);
以下では、敢えて平均を求める AVG 関数を省略して、分かりやすいように顧客IDを返すことにします。まず、答え1では、次のようになります。
SELECT customer_id
FROM Customers C1
WHERE EXISTS
(SELECT *
FROM Products P1
WHERE P1.item_id
NOT IN (SELECT D1.item_id
FROM Orders O1, OrderDetails D1
WHERE O1.customer_id = C1.customer_id
AND O1.order_id = D1.order_id));
customer_id
-----------
3
4
5
6
客1,2は、全ての製品を買っているので、これが除外されるのは正しいことです。一方、注文自体していない5,6番のような客がテーブルに含まれていた場合、これらの客まで含めてしまいます。もっとも、買っていない客に「売掛金残高」が発生することはありえないので、テーブルの構造上、こういうデータが発生することはあってはなりません。しかし、5,6番を除外するようなクエリもあれば便利です。これは皆さんも練習問題として考えてみてください。
SELECT customer_id
FROM Customers C1
WHERE (SELECT COUNT(DISTINCT item_id) -- 販売中の全製品
FROM Products) -- 対
<> (SELECT COUNT(DISTINCT item_id) -- 顧客が買った製品
FROM Orders, OrderDetails
WHERE Orders.customer_id = C1.customer_id
AND Orders.order_id = OrderDetails.order_id);
customer_id
-----------
3
4
5
6
答え1が述語論理的な解答なら、答え2はいわば集合指向的な解答。これは、製品と注文明細の間に一対一対応がつくかどうかをテストしているのです。―― そう、ここまで言えばお分かりでしょう。これは要するに関係除算なのです。となれば、私はむしろ HAVING を使って表現する方が素直だと思います。
/* 答え2-1:HAVINGを使ってより関係除算らしく */
SELECT C.customer_id
FROM Customers C
LEFT OUTER JOIN
(Orders O INNER JOIN OrderDetails OD
ON O.order_id = OD.order_id)
ON O.customer_id = C.customer_id
GROUP BY C.customer_id
HAVING COUNT(DISTINCT item_id) -- 顧客が買った製品
<> (SELECT COUNT(DISTINCT item_id) -- 販売中の全製品
FROM Products);
customer_id
-----------
3
4
5
6
もし、注文自体をしていない5,6番の客を除外したければ、外部結合を内部結合に変えるだけです。こっちのが見通しのいいクエリでしょう。しかも、注文をしている客を含めるか含めないかの切り替えも簡単で拡張性に富みます。
参考:
第32問 税金の計算
最近なにかと話題になる木構造の扱いに関する問題です。まずはテーブルを用意しましょう。
サンプルデータ
CREATE TABLE TaxAuthorities
(tax_authority CHAR(10) NOT NULL,
tax_area CHAR(10) NOT NULL,
PRIMARY KEY (tax_authority, tax_area));
CREATE TABLE TaxRates
(tax_authority CHAR(10) NOT NULL,
effect_date DATE NOT NULL,
tax_rate DECIMAL (8,2) NOT NULL,
PRIMARY KEY (tax_authority, effect_date));
--税務当局テーブル
INSERT INTO TaxAuthorities VALUES('city1', 'city1');
INSERT INTO TaxAuthorities VALUES('city2', 'city2');
INSERT INTO TaxAuthorities VALUES('city3', 'city3');
INSERT INTO TaxAuthorities VALUES('county1', 'city1');
INSERT INTO TaxAuthorities VALUES('county1', 'city2');
INSERT INTO TaxAuthorities VALUES('county2', 'city3');
INSERT INTO TaxAuthorities VALUES('state1', 'city1');
INSERT INTO TaxAuthorities VALUES('state1', 'city2');
INSERT INTO TaxAuthorities VALUES('state1', 'city3');
--税率テーブル
INSERT INTO TaxRates VALUES('city1', '1993-01-01', 1.0);
INSERT INTO TaxRates VALUES('city1', '1994-01-01', 1.5);
INSERT INTO TaxRates VALUES('city2', '1993-09-01', 1.5);
INSERT INTO TaxRates VALUES('city2', '1994-01-01', 2.0);
INSERT INTO TaxRates VALUES('city2', '1995-01-01', 2.0);
INSERT INTO TaxRates VALUES('city3', '1993-01-01', 1.7);
INSERT INTO TaxRates VALUES('city3', '1993-07-01', 1.9);
INSERT INTO TaxRates VALUES('county1', '1993-01-01' , 2.3);
INSERT INTO TaxRates VALUES('county1', '1994-10-01' , 2.5);
INSERT INTO TaxRates VALUES('county1', '1995-01-01' , 2.7);
INSERT INTO TaxRates VALUES('county2', '1993-01-01' , 2.4);
INSERT INTO TaxRates VALUES('county2', '1994-01-01' , 2.7);
INSERT INTO TaxRates VALUES('county2', '1995-01-01' , 2.8);
INSERT INTO TaxRates VALUES('state1' , '1993-01-01' , 0.5);
INSERT INTO TaxRates VALUES('state1' , '1994-01-01' , 0.8);
INSERT INTO TaxRates VALUES('state1' , '1994-07-01' , 0.9);
INSERT INTO TaxRates VALUES('state1' , '1994-10-01' , 1.1);
このテーブルは、隣接リストモデルのように見えるけどでも違う変則的なもので、逆に木構造であることが分かりにくいかもしれません。サンプルデータの構造を図示すると次のようになります。
税務当局をノードと見なした木構造
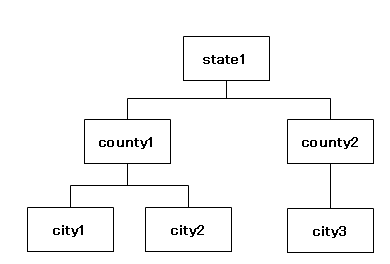
このイメージがつかめれば、答え1と2について特に問題はありません。ここでは、セルコの十八番である答え3「入れ子集合モデル」の方法を解説しておきましょう。これは、ノードを集合(円)とみなし、その入れ子関係によって階層構造を表現するモデルです。イメージは次のように変わります。
木構造を入れ子集合で表す
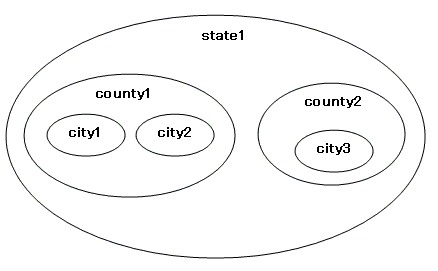
CREATE TABLE TaxRates
(tax_authority CHAR(10) NOT NULL,
lft INTEGER NOT NULL CHECK (lft > 0),
rgt INTEGER NOT NULL,
CHECK (lft < rgt),
start_date DATE NOT NULL,
end_date DATE, -- NULLならば現在の税率を意味する
tax_rate DECIMAL(8,2) NOT NULL,
PRIMARY KEY (tax_authority, start_date));
INSERT INTO TaxRates VALUES('state1', 1, 12, '1993-01-01', '1993-12-31', 0.5);
INSERT INTO TaxRates VALUES('state1', 1, 12, '1994-01-01', '1994-06-30', 0.8);
INSERT INTO TaxRates VALUES('state1', 1, 12, '1994-07-01', '1994-09-30', 0.9);
INSERT INTO TaxRates VALUES('state1', 1, 12, '1994-10-01', NULL, 1.1);
INSERT INTO TaxRates VALUES('state1', 1, 12, '1993-01-01', '1993-12-31', 0.5);
INSERT INTO TaxRates VALUES('county1', 2, 7, '1993-01-01', '1994-09-30', 2.3);
INSERT INTO TaxRates VALUES('county1', 2, 7, '1994-10-01', '1994-12-31', 2.5);
INSERT INTO TaxRates VALUES('county1', 2, 7, '1995-01-01', NULL, 2.7);
INSERT INTO TaxRates VALUES('county2', 8, 11, '1993-01-01', '1993-12-31', 2.4);
INSERT INTO TaxRates VALUES('county2', 8, 11, '1994-01-01', '1994-12-31', 2.7);
INSERT INTO TaxRates VALUES('county2', 8, 11, '1995-01-01', NULL, 2.8);
INSERT INTO TaxRates VALUES('city1', 3, 4, '1993-01-01', '1993-12-31', 1.0);
INSERT INTO TaxRates VALUES('city1', 3, 4, '1994-01-01', NULL, 1.5);
INSERT INTO TaxRates VALUES('city2', 5, 6, '1993-01-01', '1993-12-31', 1.5);
INSERT INTO TaxRates VALUES('city2', 5, 6, '1994-01-01', '1994-12-31', 2.0);
INSERT INTO TaxRates VALUES('city2', 5, 6, '1995-01-01', NULL, 2.0);
INSERT INTO TaxRates VALUES('city3', 9, 10, '1993-01-01', '1993-06-30', 1.7);
INSERT INTO TaxRates VALUES('city3', 9, 10, '1993-07-01', NULL, 1.9);
時間が経過するにつれて税率が変わるので、一つの税務当局を複数レコード登録する点は同じです。では、答え1,2と同様に1994年11月01日時点での「city2」に適用される税率を求めてみましょう。
SELECT SUM(DISTINCT T2.tax_rate) AS total_taxes
FROM TaxRates T1, TaxRates T2
WHERE T1.tax_authority = 'city2'
AND '1994-11-01' BETWEEN T2.start_date
AND COALESCE (T2.end_date, CURRENT_DATE)
AND T1.lft BETWEEN T2.lft AND T2.rgt;
total_taxes
-----------
5.6
「city2」を含むような円(自分もカウントする)を、BETWEEN 述語で探しているわけです。クエリがずっと簡単で直観的になります。
参考:
第33問 機械の平均使用コストの計算
いわゆる「減価償却費」を考慮して、機械を使うたびにかかる平均コスト、つまり累計的な平均を算出する問題です(「累均」という言葉はないでしょうけど、敢えて呼ぶならそんな感じ)。減価償却の計算方法には定額法と定率法の二種類がありますが、この問題では定額法、すなわち毎日一定額が引かれていく計算法を採用しています。initial_cost / lifespan で求めているのがそうで、この問題では 10ドル/日 です。
サンプルデータ
CREATE TABLE Machines
(machine_name CHAR(20) NOT NULL PRIMARY KEY,
purchase_date DATE NOT NULL,
initial_cost DECIMAL (10,2) NOT NULL,
lifespan INTEGER NOT NULL);
CREATE TABLE ManufactHrsCosts
(machine_name CHAR(20) NOT NULL
REFERENCES Machines(machine_name),
manu_date DATE NOT NULL,
batch_nbr INTEGER NOT NULL,
manu_hrs DECIMAL(4,2) NOT NULL,
manu_cost DECIMAL (6,2) NOT NULL,
PRIMARY KEY (machine_name, manu_date, batch_nbr));
--機械テーブル
INSERT INTO Machines VALUES('Frammis', '1995-07-24', 10000, 1000);
--作業時間コストテーブル
INSERT INTO ManufactHrsCosts VALUES('Frammis', '1995-07-24', 101, 2.5, 123.00);
INSERT INTO ManufactHrsCosts VALUES('Frammis', '1995-07-25', 102, 2.5, 120.00);
INSERT INTO ManufactHrsCosts VALUES('Frammis', '1995-07-25', 103, 2.0, 100.00);
INSERT INTO ManufactHrsCosts VALUES('Frammis', '1995-07-26', 104, 2.5, 118.00);
INSERT INTO ManufactHrsCosts VALUES('Frammis', '1995-07-27', 105, 2.5, 116.00);
INSERT INTO ManufactHrsCosts VALUES('Frammis', '1995-07-27', 106, 2.5, 113.00);
INSERT INTO ManufactHrsCosts VALUES('Frammis', '1995-07-28', 107, 2.5, 110.00);
平均コストを求める計算式は、「(:mydate までの総償却費 + :mydate までの総使用コスト)/ (:mydate までの総使用時間)」です。
累計的な数値を求めるわけですから、この問題には OLAP 関数を使った解法もあると思います。皆さんも考えてみてください。
第34問 コンサルタントの請求書
給料 = 労働時間 × 時給。これだけならどうってことない計算ですが、厄介なのは、時給が刻々と変化していくことです。実際、労働者には昇給もあれば減給もあるのだから、これは現実的な要件といわねばなりません。この点で、税率が期間ごとに変動した「32.税金の計算」の要件とよく似ています。やはりこの問題においても、ある時点でのコンサルタントの時給を求める工夫がキモです。
サンプルデータ
CREATE TABLE Consultants
(emp_id INTEGER NOT NULL,
emp_name CHAR(10) NOT NULL);
CREATE TABLE Billings
(emp_id INTEGER NOT NULL,
bill_date DATE NOT NULL,
bill_rate DECIMAL (5,2));
CREATE TABLE HoursWorked
(job_id INTEGER NOT NULL,
emp_id INTEGER NOT NULL,
work_date DATE NOT NULL,
bill_hrs DECIMAL(5, 2));
INSERT INTO Consultants VALUES (1, 'Larry');
INSERT INTO Consultants VALUES (2, 'Moe');
INSERT INTO Consultants VALUES (3, 'Curly');
INSERT INTO Billings VALUES (1, '1990-01-01', 25.00);
INSERT INTO Billings VALUES (2, '1989-01-01', 15.00);
INSERT INTO Billings VALUES (3, '1989-01-01', 20.00);
INSERT INTO Billings VALUES (1, '1991-01-01', 30.00);
INSERT INTO HoursWorked VALUES (4, 1, '1990-07-01', 3);
INSERT INTO HoursWorked VALUES (4, 1, '1990-08-01', 5);
INSERT INTO HoursWorked VALUES (4, 2, '1990-07-01', 2);
INSERT INTO HoursWorked VALUES (4, 1, '1991-07-01', 4);
適切な時給を求めるには、実働日より前の「直近の請求日」を求める必要があります。従ってこれもまた、「30.買い物の平均サイクル」と同じく最大下界を求める問題なのです。
第36問 1人2役
私の大好きな CASE 式の応用問題です。SELECT句では CASE 式の中に集約関数を組み込めるという素晴らしい特性を利用した方法ですね。こんなことが可能なのは、SELECT 句では集約関数も一つの値に定まっているため、式(関数)の引数に使うことが何の問題もなく可能だからです。
サンプルデータ
CREATE TABLE Roles(
person VARCHAR2(32),
role VARCHAR2(32),
PRIMARY KEY (person, role));
INSERT INTO Roles VALUES('Smith', 'O');
INSERT INTO Roles VALUES('Smith', 'D');
INSERT INTO Roles VALUES('Jones', 'O');
INSERT INTO Roles VALUES('White', 'D');
INSERT INTO Roles VALUES('Brown', 'X');
ちなみに、答え4で「THEN role」ではなく「THEN MAX(role)」としなければ動かない DB というのは、例えば、Oracle や MySQL がそうです。ちょっと気が利かない。というか、これを動的に判断できる PostgreSQL などが気が利いている、というべきかな。
それにしても、答え5の共役性の利用はトリッキーです。エレガントで高速な素晴らしい解答ですが、この本の中でも屈指のアクロバティックな部類に入ります。なお、PostgreSQL では、型チェックが厳しくて、SUM 関数の戻り値を整数型に変換しないと正しく動かないので注意。
--PostgreSQL版
SELECT person,
SUBSTRING ('DOB', CAST(SUM (POSITION (role IN 'DO')) AS INTEGER), 1)
FROM Roles
WHERE role IN ('D','O')
GROUP BY person;
第35問 在庫調整
この問題は、SQL の集合指向言語としての面目躍如です。でも、最初に身も蓋もないこと言っちゃうと、OLAP 関数が使える DB なら答え3を使ってください。今さらスカラ・サブクエリに敢えて頼る必要はありません。
サンプルデータ
CREATE TABLE InventoryAdjustments
(req_date DATE NOT NULL,
req_qty INTEGER NOT NULL
CHECK (req_qty <> 0),
PRIMARY KEY (req_date, req_qty));
INSERT INTO InventoryAdjustments VALUES('1994-07-01', 100 );
INSERT INTO InventoryAdjustments VALUES('1994-07-02', 120 );
INSERT INTO InventoryAdjustments VALUES('1994-07-03', -150);
INSERT INTO InventoryAdjustments VALUES('1994-07-04', 50 );
INSERT INTO InventoryAdjustments VALUES('1994-07-05', -35 );
この問題は、訳注にも書いたように、ノイマン型の同心円的な再帰集合を使って累計を求める問題です。私はこのアプローチについてはけっこう詳しく解説したテキストをいくつか書いているので、興味ある方は以下を参照してください。
参考:
第37問 移動平均
移動平均は、統計分析でよく使われる指標です。OLAP 関数が使える環境なら、答え4を使ってください。そうでない場合は、相関サブクエリや自己結合に頼らねばなりません。
サンプルデータ
CREATE TABLE Samples
(sample_time TIMESTAMP NOT NULL PRIMARY KEY,
moving_avg REAL DEFAULT 0 NOT NULL ,
load REAL DEFAULT 0 NOT NULL);
INSERT INTO Samples VALUES('2007-01-01 01:00', 0, 0);
INSERT INTO Samples VALUES('2007-01-01 01:15', 0, 1);
INSERT INTO Samples VALUES('2007-01-01 01:30', 0, 2);
INSERT INTO Samples VALUES('2007-01-01 01:45', 0, 3);
INSERT INTO Samples VALUES('2007-01-01 02:00', 0, 4);
INSERT INTO Samples VALUES('2007-01-01 02:15', 0, 5);
INSERT INTO Samples VALUES('2007-01-01 02:30', 0, 6);
移動平均のイメージは、言葉で説明するより、結果で見たほうが分かりやすいでしょう。
SELECT S1.sample_time, AVG(S2.load) AS avg_prev_hour_load
FROM Samples S1, Samples S2
WHERE S2.sample_time BETWEEN (S1.sample_time - INTERVAL '1' HOUR)
AND S1.sample_time
GROUP BY S1.sample_time;
sample_time avg_prev_hour_load
----------------- ------------------
20-07-01 01:00:00 0
20-07-01 01:15:00 0.5
20-07-01 01:30:00 1
20-07-01 01:45:00 1.5
20-07-01 02:00:00 2
20-07-01 02:15:00 3
20-07-01 02:30:00 4
例えば、2時00分時点での平均は、過去1時間分の平均なので、(0 + 1 + 2 + 3 + 4)/ 5 = 2、その次の2時15分時点での平均は、(1 + 2 + 3 + 4 + 5)/ 5 = 3、と、計算対象となる集合の要素が一行ずつズレていくのです。
参考:
第38問 記録の更新
30番台の問題は、最大下界を求めるものばかりでしたが、今回はその裏返しで、最小上界を求めます。といっても、基本的な考え方は同じなので臆することはありません。
サンプルデータ
CREATE TABLE Journal
(acct_nbr INTEGER NOT NULL,
trx_date DATE NOT NULL,
trx_amt DECIMAL (10, 2) NOT NULL,
duration INTEGER NOT NULL);
INSERT INTO Journal VALUES(1, '2007-01-01', 10, 0);
INSERT INTO Journal VALUES(1, '2007-01-02', 20, 0);
INSERT INTO Journal VALUES(1, '2007-01-04', 30, 0);
INSERT INTO Journal VALUES(2, '2007-01-07', 40, 0);
INSERT INTO Journal VALUES(2, '2007-01-11', 50, 0);
INSERT INTO Journal VALUES(3, '2007-01-20', 60, 0);
INSERT INTO Journal VALUES(4, '2007-01-01', 70, 0);
INSERT INTO Journal VALUES(4, '2007-01-02', 80, 0);
答え1〜4のいずれの解も、次のような結果になります。ある日を起点にして、その直後の日付、いわば「未来の直近」を求めるのがミソです。これが最小上界ですね。あとは日付同士を引き算して日数を割り出すだけ。「〜日前」と過去へ遡る日数なので、マイナスで表現しています。
更新結果:
acct_nbr trx_date trx_amt duration
-------- -------- ------- --------
1 07-01-01 10 -1
1 07-01-02 20 -2
1 07-01-04 30 0
2 07-01-07 40 -4
2 07-01-11 50 0
3 07-01-20 60 0
4 07-01-01 70 -1
4 07-01-02 80 0
答え1〜3は、いずれもテーブルを直に更新する方法ですが、答え1,2が更新対象行だけを更新するのに対し、WHERE句のない答え3は全行を更新する、という点が違います。この点で、本文にもあるようにパフォーマンス上の違いが出るでしょう。
第39問 保険損失
Losses テーブルを見た瞬間、「あー、あるある」と思った人も多いでしょう。配列やフラットファイルのデータを何も考えずにテーブルに移した擬似配列テーブルです。パズル24に続いての登場です。リレーショナル・データベースにおいて、列持ちテーブルを使うメリットはほとんどありません。せいぜい、出力するアウトプットの形とあわせればクエリが簡単になる、という程度で、拡張性や柔軟性はゼロ。反対に行持ちにしておけば、この問題で見るように結合も簡単、列持ちへの再変換も CASE 式を使えば楽勝。従って、こういう列持ち形式のテーブルは、見つけ次第すぐに行持ち形式に変換することです。
テーブル設計の鉄則:列持ちのメリットはほとんどない。速攻で行持ちへ変換せよ。
サンプルデータ
CREATE TABLE Losses
(cust_nbr INTEGER NOT NULL PRIMARY KEY,
a INTEGER, b INTEGER, c INTEGER, d INTEGER, e INTEGER,
f INTEGER, g INTEGER, h INTEGER, i INTEGER, j INTEGER,
k INTEGER, l INTEGER, m INTEGER, n INTEGER, o INTEGER);
CREATE TABLE Policy_Criteria
(criteria_id INTEGER NOT NULL,
criteria CHAR(1) NOT NULL,
crit_val INTEGER NOT NULL,
PRIMARY KEY (criteria_id, criteria, crit_val));
CREATE TABLE LossDoneRight
(cust_nbr INTEGER NOT NULL,
criteria CHAR(1) NOT NULL,
crit_val INTEGER NOT NULL);
INSERT INTO Losses
VALUES ( 99, 5, 10, 15, NULL, NULL, NULL, NULL, NULL,
NULL, NULL,NULL, NULL, NULL, NULL, NULL);
INSERT INTO Policy_Criteria VALUES (1, 'A', 5);
INSERT INTO Policy_Criteria VALUES (1, 'A', 9);
INSERT INTO Policy_Criteria VALUES (1, 'A', 14);
INSERT INTO Policy_Criteria VALUES (1, 'B', 4);
INSERT INTO Policy_Criteria VALUES (1, 'B', 10);
INSERT INTO Policy_Criteria VALUES (1, 'B', 20);
INSERT INTO Policy_Criteria VALUES (2, 'B', 10);
INSERT INTO Policy_Criteria VALUES (2, 'B', 19);
INSERT INTO Policy_Criteria VALUES (3, 'A', 5);
INSERT INTO Policy_Criteria VALUES (3, 'B', 10);
INSERT INTO Policy_Criteria VALUES (3, 'B', 30);
INSERT INTO Policy_Criteria VALUES (3, 'C', 3);
INSERT INTO Policy_Criteria VALUES (3, 'C', 15);
INSERT INTO Policy_Criteria VALUES (4, 'A', 5);
INSERT INTO Policy_Criteria VALUES (4, 'B', 21);
INSERT INTO Policy_Criteria VALUES (4, 'B', 22);
答え1のコードを使って行持ちに変換した後の LossDoneRight は次のようになります。このテーブル、主キーが設定されていないんですが、一応 (cust_nbr, criteria) に付けておくのが良いでしょう。
cust_nbr criteria crit_val
-------- -------- --------
99 A 5
99 B 10
99 C 15
この形式にできたら、後は関係除算をするだけです。答え2の拡張版のクエリについて、セルコはパフォーマンスを懸念していますが、実際はどちらも主キーのインデックスが使えるので、そんなに心配することはないと思います。
第40問 順列
これはなかなか面白い問題です。基本的な考え方としては、訳注で説明したとおりです。数字が書かれた玉の入った袋を想像しましょう。 Elements テーブルがその袋です。SQL で Elements テーブルから要素を選択しても、それだけでテーブルから要素が消えるわけではありません。しかし、次の選択時に、既に選択済みの要素を除外する条件をつけることで、玉がどんどん減っていくのと同じ効果を実現できるわけです。
サンプルデータ
CREATE TABLE Elements
(i INTEGER NOT NULL PRIMARY KEY);
INSERT INTO Elements VALUES (1);
INSERT INTO Elements VALUES (2);
INSERT INTO Elements VALUES (3);
INSERT INTO Elements VALUES (4);
INSERT INTO Elements VALUES (5);
INSERT INTO Elements VALUES (6);
INSERT INTO Elements VALUES (7);
この問題のクエリを実行すると、結果が 7! = 5040行返ってきます。自己結合の嵐で実行コストも高いので、低性能のマシンで実行する場合はちょっと遅いかも。ちなみに、答え5は、STUFF 関数を持っている SQLServer でのみ動きます(セルコは「多くのRDBMSが持っている」というけど、実は SQLServer しか持っていない)。
参考:
第41問 予算
この問題は、見た目は複雑に見えるかもしれませんが、一つ一つの結合にバラして考えれば、やっていることは至って単純です。要は、商品マスタ、予算、実費の三つのテーブルを外部結合したいわけですが、結合キーの item_nbr では主キーにならないため、そのまま結合すると多対多の結合になり、結果の数値がおかしくなります。これを防ぐため、あらかじめ item_nbr をキーに集約しておいてから ―― そうすれば item_nbr が一意キーになる ―― 結合しているのです。
サンプルデータ
CREATE TABLE Items
(item_nbr INTEGER,
item_descr CHAR(10));
CREATE TABLE Actuals
(item_nbr INTEGER,
actual_amt DECIMAL(5,2),
check_nbr CHAR(4));
CREATE TABLE Estimates
(item_nbr INTEGER,
estimated_amt DECIMAL(5,2));
INSERT INTO Items VALUES(10, 'Item 10');
INSERT INTO Items VALUES(20, 'Item 20');
INSERT INTO Items VALUES(30, 'Item 30');
INSERT INTO Items VALUES(40, 'Item 40');
INSERT INTO Items VALUES(50, 'item 50');
INSERT INTO Actuals VALUES(10, 300.00, '1111');
INSERT INTO Actuals VALUES(20, 325.00, '2222');
INSERT INTO Actuals VALUES(20, 100.00, '3333');
INSERT INTO Actuals VALUES(30, 525.00, '1111');
INSERT INTO Estimates VALUES(10, 300.00);
INSERT INTO Estimates VALUES(10, 50.00);
INSERT INTO Estimates VALUES(20, 325.00);
INSERT INTO Estimates VALUES(20, 110.00);
INSERT INTO Estimates VALUES(40, 25.00);
なお、答え1,2の両方に存在する「WHERE actual_amt IS NOT NULL OR estimated_amt IS NOT NULL」という条件は、商品テーブルには存在するけど、結局購入しなかった 50 番のような商品を除外するための条件です。もしとにかく全部の商品を一覧表示したいなら、この条件は不要です。
第42問 魚のサンプリング調査
サブタイトルは「存在しないデータの集計」。この時点ですでに、なにやら矛盾した響きを帯びています。普通、集計って存在するデータをするものでしょ? はい、おおせのとおり。この問題は、そもそもテーブルに問題があるのです。本文にもありますが、サンプル調査する魚の種類が決まってるなら、それが1匹も捕まえられなかったときも「0匹」という行を追加してやるべきです。ちょうど、「第2問 欠勤」で、罰点が0の行を登録しておくことが重要な意味を持っていたのと同じです。
サンプルデータ
CREATE TABLE Samples
(sample_id INTEGER NOT NULL,
fish_name CHAR(20) NOT NULL,
found_tally INTEGER NOT NULL,
PRIMARY KEY (sample_id, fish_name));
CREATE TABLE SampleGroups
(group_id INTEGER NOT NULL,
group_descr CHAR(20) NOT NULL,
sample_id INTEGER NOT NULL,
PRIMARY KEY (group_id, sample_id));
INSERT INTO Samples VALUES (1, 'minnow', 18);
INSERT INTO Samples VALUES (1, 'pike', 7);
INSERT INTO Samples VALUES (2, 'pike', 4);
INSERT INTO Samples VALUES (2, 'carp', 3);
INSERT INTO Samples VALUES (3, 'carp', 9);
INSERT INTO SampleGroups VALUES (1, 'muddy water', 1);
INSERT INTO SampleGroups VALUES (1, 'muddy water', 2);
INSERT INTO SampleGroups VALUES (2, 'fresh water', 1);
INSERT INTO SampleGroups VALUES (2, 'fresh water', 3);
INSERT INTO SampleGroups VALUES (2, 'fresh water', 2);
また、問題の最後に注意が述べられている「ありえないデータ」を追加した状態で、答え1と答え2,3の結果を比較してみたいなら、
INSERT INTO SampleGroups VALUES (2, 'fresh water', 4);
というデータを追加するのがいいでしょう。sample_id 「4」は、Samples テーブルに存在しないデータですから、本当はこれが SampleGroups に含まれることはありえないはずです。
第43問 卒業
これもなかなか高度な CASE 式の応用です。基本的には、CASE 式の中に集約関数を組み込むタイプなので、「36問 1人2役」などと同じパターンなのですが、今回はさらに「(SELECT COUNT(*) FROM Categories)」というスカラ・サブクエリまで入力にとってしまおうという力業。
サンプルデータ
CREATE TABLE Categories
(credit_cat CHAR(1) NOT NULL,
rqd_credits INTEGER NOT NULL);
CREATE TABLE CreditsEarned --主キーなし
(student_name CHAR(10) NOT NULL,
credit_cat CHAR(1) NOT NULL,
credits INTEGER NOT NULL);
INSERT INTO Categories VALUES ('A', 10);
INSERT INTO Categories VALUES ('B', 3);
INSERT INTO Categories VALUES ('C', 5);
INSERT INTO CreditsEarned
VALUES ('Joe', 'A', 3), ('Joe', 'A', 2), ('Joe', 'A', 3),
('Joe', 'A', 3), ('Joe', 'B', 3), ('Joe', 'C', 3),
('Joe', 'C', 2), ('Joe', 'C', 3),
('Bob', 'A', 2), ('Bob', 'C', 2), ('Bob', 'A', 12),
('Bob', 'C', 4),
('John', 'A', 1), ('John', 'B', 1),
('Mary', 'A', 1), ('Mary', 'A', 1), ('Mary', 'A', 1),
('Mary', 'A', 1), ('Mary', 'A', 1), ('Mary', 'A', 1),
('Mary', 'A', 1), ('Mary', 'A', 1), ('Mary', 'A', 1),
('Mary', 'A', 1), ('Mary', 'A', 1), ('Mary', 'B', 1),
('Mary', 'B', 1), ('Mary', 'B', 1), ('Mary', 'B', 1),
('Mary', 'B', 1), ('Mary', 'B', 1), ('Mary', 'B', 1),
('Mary', 'C', 1), ('Mary', 'C', 1), ('Mary', 'C', 1),
('Mary', 'C', 1), ('Mary', 'C', 1), ('Mary', 'C', 1),
('Mary', 'C', 1), ('Mary', 'C', 1);
さあ皆さん、ご一緒に。CASE 式最強!
第44問 商品のペア
引き続き CASE 式祭り。今回は、CASE 式の使い方もさることながら、非等値結合の使い方もポイントです。何やってるかというと、要するにこれは、順列を組み合わせに変換しているんです。(12345, 67890)と(67890, 12345)というペアは、順列、すなわち順序集合としてみた場合は、異なる存在と考えられます。でも、組み合わせ、すなわち非順序集合としてみた場合は、どっちも同じです。非等値結合は、SQL で組み合わせ問題を解くときの強力な武器です。
サンプルデータ
CREATE TABLE SalesSlips
(item_a INTEGER NOT NULL,
item_b INTEGER NOT NULL,
PRIMARY KEY(item_a, item_b),
pair_tally INTEGER NOT NULL);
INSERT INTO SalesSlips VALUES(12345, 12345, 12);
INSERT INTO SalesSlips VALUES(12345, 67890, 9);
INSERT INTO SalesSlips VALUES(67890, 12345, 5);
参考:
第45問 ペパロニピザ
この問題にはテーブル定義が載っていないので、私が考える DDL を示します。問題自体は、CASE 式による水平展開です。こういう時系列のレポートでは、期間を列持ちで出力したいというケースも多いので、非常に重宝します。
サンプルデータ
--重複行があるというので、主キーなし
CREATE TABLE FriendsofPepperoni
(cust_id INTEGER,
bill_date DATE,
pizza_amt DECIMAL(5,2));
--答え3用マスタテーブル
CREATE TABLE ReportRanges
(day_count CHAR(32),
start_cnt INTEGER,
end_cnt INTEGER);
INSERT INTO FriendsofPepperoni VALUES(1, '2007-05-07', 10);
INSERT INTO FriendsofPepperoni VALUES(1, '2007-04-01', 20);
INSERT INTO FriendsofPepperoni VALUES(1, '2007-03-01', 30);
INSERT INTO FriendsofPepperoni VALUES(1, '2007-01-01', 40);
INSERT INTO FriendsofPepperoni VALUES(2, '2007-05-06', 10);
INSERT INTO FriendsofPepperoni VALUES(2, '2007-04-01', 20);
INSERT INTO FriendsofPepperoni VALUES(2, '2007-03-01', 30);
INSERT INTO FriendsofPepperoni VALUES(2, '2007-01-01', 40);
--答え3用
INSERT INTO ReportRanges VALUES('under Thirty days', 00, 30);
INSERT INTO ReportRanges VALUES('Sixty days', 31, 60);
INSERT INTO ReportRanges VALUES('Ninty days', 61, 90);
以下の結果は、CURRENT_DATE = 2007年6月1日として実行したものです(当然ですが、このクエリの結果は、テーブルに変更がなくても毎日変化します)。
SELECT cust_id,
SUM(CASE WHEN bill_date BETWEEN CURRENT_DATE - INTERVAL '30' DAY
AND CURRENT_DATE
THEN pizza_amt ELSE 0.00 END) AS age1,
SUM(CASE WHEN bill_date BETWEEN CURRENT_DATE - INTERVAL '60' DAY
AND CURRENT_DATE - INTERVAL '31' DAY
THEN pizza_amt ELSE 0.00 END) AS age2,
SUM(CASE WHEN bill_date BETWEEN CURRENT_DATE - INTERVAL '90' DAY
AND CURRENT_DATE - INTERVAL '61' DAY
THEN pizza_amt ELSE 0.00 END) AS age3,
SUM(CASE WHEN bill_date < CURRENT_DATE - INTERVAL '91' DAY
THEN pizza_amt ELSE 0.00 END) AS age4
FROM FriendsofPepperoni
GROUP BY cust_id
ORDER BY cust_id;
cust_id age1 age2 age3 age4
------- ----- ----- ----- -----
1 10.00 0.00 20.00 70.00
2 10.00 0.00 20.00 70.00
ご覧のように、テーブルでは行持ちだった期間が列持ちの形式で表現されています。
第46問 販売促進
期間ごとに数値データを集約し、その中からさらに最大値を探すという問題です。これもかなりよく見かける業務要件でしょう。
サンプルデータ
CREATE TABLE Promotions
(promo_name CHAR(25) NOT NULL PRIMARY KEY,
start_date DATE NOT NULL,
end_date DATE NOT NULL,
CHECK (start_date <= end_date));
CREATE TABLE Sales
(ticket_nbr INTEGER NOT NULL PRIMARY KEY,
clerk_name CHAR (15) NOT NULL,
sale_date DATE NOT NULL,
sale_amt DECIMAL (8,2) NOT NULL);
INSERT INTO Promotions VALUES('Feast of St. Fred' ,'1995-02-01' ,'1995-02-07');
INSERT INTO Promotions VALUES('National Pickle Pageant' ,'1995-11-01' ,'1995-11-07');
INSERT INTO Promotions VALUES('Christmas Week' ,'1995-12-18' ,'1995-12-25');
INSERT INTO Sales VALUES(1, 'スミス', '1995-02-01', 10);
INSERT INTO Sales VALUES(2, 'ジョン', '1995-02-02', 20);
INSERT INTO Sales VALUES(3, 'ジョン', '1995-02-03', 30);
INSERT INTO Sales VALUES(4, 'ジョン', '1995-02-04', 20);
INSERT INTO Sales VALUES(5, 'メアリ', '1995-02-05', 70);
INSERT INTO Sales VALUES(6, 'ケン', '1995-11-03', 10);
INSERT INTO Sales VALUES(7, 'テリー', '1995-11-05', 20);
INSERT INTO Sales VALUES(8, 'テリー', '1995-11-05', 20);
上のサンプル・データを使う場合、いずれの答えも結果は次のようになります。
clerk_name promo_name sales_tot
---------- ----------------------- -----------
ジョン Feast of St. Fred 70.00
メアリ Feast of St. Fred 70.00
テリー National Pickle Pageant 40.00
「Feast of St. Fred」の期間では、ジョンとメアリーが同点で首位のため、二人が結果に現れます。「Christmas Week」の期間については、売上データが存在しないため、結果にも出てきません。もしこれを結果に含めたい場合は、外部結合を使いましょう。
第47問 座席のブロック
この問題は・・・扱いが難しいんですよね。というのも、本文にも懸念が表明されているように、CHECK 制約の中でサブクエリを使うことのできる DB がまだほとんどないからです。Oracle、PostgreSQL、MySQL はいずれもダメ。DB2 と SQLServer はどうでしょうか。
そこでここでは、制約としてではなく、既に登録されているデータに対して、期間の重複を調べるクエリに形を修正したものを紹介しましょう。
第48問 非グループ化
これは練習問題としては非常に面白いのですが、関係モデルの理論上は大きな問題を孕んでいます。それはもちろん、結果が重複行を含むため一意にならず、関係ではなくなってしまう、ということです。従って、SQL はこの「逆カウント」演算子を持っていませんし、将来的にも持つことはないでしょう。実務においても、もしこんなことをする必要に迫られたとしたら、テーブル設計に根本的な間違いがあるのだ、と思ってください(入力データが最初からこの形だったらしょうがないけど)。
サンプルデータ
CREATE TABLE Inventory
(goods CHAR(10) NOT NULL PRIMARY KEY,
pieces INTEGER NOT NULL CHECK (pieces >= 0));
INSERT INTO Inventory VALUES('Alpha' , 4);
INSERT INTO Inventory VALUES('Beta' , 5);
INSERT INTO Inventory VALUES('Delta' ,16);
INSERT INTO Inventory VALUES('Gamma' ,50);
INSERT INTO Inventory VALUES('Epsilon', 1);
解法として見事なのは、何と言っても連番テーブルを巧みに利用した答え3です。この連番テーブルは、用意しておくと本当に何かと便利です。この後も、色々なパズルで顔を出します。
参考:
第49問 部品の数
生産管理などの仕事では、製品を100個なら100個の同じサイズの集合に等分割して、その集合ごとに不良品率を調べたりします。今回の問題もそういうケース・スタディの一種だと考えると理解しやすいでしょう。
サンプルデータ
CREATE TABLE Production
(production_center INTEGER NOT NULL,
wk_date DATE NOT NULL,
batch_nbr INTEGER NOT NULL,
widget_cnt INTEGER NOT NULL,
PRIMARY KEY (production_center, wk_date, batch_nbr));
INSERT INTO Production VALUES(1, '2007-05-02', 1, 1);
INSERT INTO Production VALUES(1, '2007-05-02', 2, 2);
INSERT INTO Production VALUES(1, '2007-05-02', 3, 3);
INSERT INTO Production VALUES(1, '2007-05-02', 4, 4);
INSERT INTO Production VALUES(1, '2007-05-02', 5, 5);
INSERT INTO Production VALUES(1, '2007-05-02', 6, 6);
INSERT INTO Production VALUES(1, '2007-05-02', 7, 7);
INSERT INTO Production VALUES(1, '2007-10-02', 1, 1);
INSERT INTO Production VALUES(1, '2007-10-02', 2, 2);
INSERT INTO Production VALUES(1, '2007-10-02', 3, 3);
Prod3 ビューは次のような3分割した内容になります。
wk_date widget_cnt third
---------- ---------- -----
2007-05-02 1 1
2007-05-02 2 1
2007-05-02 3 2
2007-05-02 4 2
2007-05-02 5 3
2007-05-02 6 3
2007-05-02 7 3
2007-10-02 1 1
2007-10-02 2 2
2007-10-02 3 3
5月2日には、全部で7個のバッチ処理が行われたため、2・2・3 という分割です。3で割り切れない分については、最後のグループで埋め合わせています。一方、10月2日のバッチは三つなので、綺麗に 1・1・1 と分割できています。
ちなみに、Oracle の持つ NTILE 関数を使うと、次のような簡潔なクエリで同じことができます。
SELECT production_center, wk_date, third, AVG(widget_cnt)
FROM (SELECT production_center, wk_date,
NTILE(3) OVER (PARTITION BY production_center, wk_date
ORDER BY batch_nbr ASC) third,
widget_cnt
FROM production)
GROUP BY production_center, wk_date, third;
NTILE(3) で「三分割」の意味になることからも分かるように、NTILE 関数は引数に分割したい集合の数を指定します。この関数も、統計分析の際になかなか便利な働きをします(例えば、100分割して上下二つを除外することで外れ値を取り除く、といった使い方)。
第50問 3分の2
これは関係除算の変形です。普通の関係除算が「全ての分野で論文を書いている」著者を抜き出すものであるのに対し、それを任意の部分集合の場合にも適用できるように一般化したものです。
サンプルデータ
CREATE TABLE AnthologyContributors
(isbn CHAR(10) NOT NULL,
contributor CHAR(20) NOT NULL,
category INTEGER NOT NULL,
PRIMARY KEY (isbn, contributor));
INSERT INTO AnthologyContributors VALUES(1, 'スミス', 1);
INSERT INTO AnthologyContributors VALUES(2, 'スミス', 2);
INSERT INTO AnthologyContributors VALUES(3, 'スミス', 3);
INSERT INTO AnthologyContributors VALUES(4, 'ジョン', 1);
INSERT INTO AnthologyContributors VALUES(5, 'ジョン', 2);
INSERT INTO AnthologyContributors VALUES(6, 'メアリ', 1);
INSERT INTO AnthologyContributors VALUES(7, 'メアリ', 1);
INSERT INTO AnthologyContributors VALUES(8, 'ガトー', 2);
INSERT INTO AnthologyContributors VALUES(9, 'ガトー', 3);
INSERT INTO AnthologyContributors VALUES(10,'シモン', 1);
例えば、上のサンプルデータならば、1、2、3の三つの分野のうち二つに論文を書いている著者ということで、ジョンとガトーが該当します。メアリは、一つの分野に二つ書いているので、この問題では除外されます。
面白いのは、「三つ目の分野に執筆していない」という条件を追加した類題を解くための答えその5です。試しに、「分野1と2に執筆しているが、3には執筆していない」という条件を考えましょう。この場合、結果はジョンだけになります。
SELECT contributor, 1, 2, 3
FROM AnthologyContributors AS A1
WHERE A1.category IN (1, 2, 3)
GROUP BY contributor
HAVING (SELECT SUM(DISTINCT
CASE WHEN category = 1
THEN 1
WHEN category = 2
THEN 2
WHEN category = 3
THEN -3 ELSE NULL END)) = 3;
contributor cat_1 cat_2 cat_3
----------- ----- ----- -----
ジョン 1 2 3
CASE式は、もし分野1について書いていれば1を返し、分野2について書いていれば2を返し、そして、分野3について書いていれば3を返します。ということは、合計が 3 になるケースというのは、結局、分野1と2の両方に書いていて、分野3については書いていない場合だけ、なのです。このトリックは、「第36問 1人2役」の答え5とよく似ていますね。
第51問 予算と実支出の対比
第41問と同じような会計問題です。今回の問題でも、やはりポイントは、結合キー の category が1対多になることをうまく回避することです。答え1は、オーソドクスに集約することで 1対1 の関係にしています。
サンプルデータ
INSERT INTO Budgeted VALUES(1, 9100, 100.00);
INSERT INTO Budgeted VALUES(2, 9100, 15.00);
INSERT INTO Budgeted VALUES(3, 9100, 6.00);
INSERT INTO Budgeted VALUES(4, 9200, 8.00);
INSERT INTO Budgeted VALUES(5, 9200, 11.00);
INSERT INTO Actual VALUES(1, 1, 10.00);
INSERT INTO Actual VALUES(2, 1, 20.00);
INSERT INTO Actual VALUES(3, 1, 15.00);
INSERT INTO Actual VALUES(4, 2, 32.00);
INSERT INTO Actual VALUES(5, 4, 8.00);
INSERT INTO Actual VALUES(6, 5, 3.00);
INSERT INTO Actual VALUES(7, 5, 4.00);
この問題で非常に面白いのは、答え2です。これは、ある程度 SQL に慣れた人なら、即座に「構文エラーではないか?」という反応をするはずです。私たちは、WHERE句では集約関数や極値関数は使えないと教わってきますが、このクエリは堂々と使っているではありませんか!
--構文エラー!?
SELECT category, SUM(B1.est_cost) AS estimated,
(SELECT SUM(T1.act_cost)
FROM Actual AS T1
WHERE T1.task BETWEEN MIN(B1.task)
AND MAX(B1.task)) AS spent
FROM Budgeted AS B1
GROUP BY category;
category estimated spent
-------- --------- -----
9200 19.00 15.00
9100 121.00 77.00
ところがどっこい。これはちゃんとした SQL なんです。秘密は、外側で category をキーに集約していることです。これによって、B1 テーブルの列で直接参照可能なのは、category だけとなり、他の task や est_cost などはそのままでは使えなくなるのです。代わりに、集約関数の引数とすることで参照できるようになります。ただし、これはやはり非常にトリッキーな方法なので、Oracle や MySQL では正しく動きません。PostgreSQL では正しく動作します。
参考:
第52問 部署の平均人数
2段階の集約というのは、ときどき見かける要件ですが、基本的には問題文にあるように、ビュー(またインライン・ビュー)を使って実現することになります。
サンプルデータ
CREATE TABLE Personnel
(emp_name CHAR(10) NOT NULL,
dept_id CHAR(10) );
INSERT INTO Personnel VALUES('Daren', 'Acct');
INSERT INTO Personnel VALUES('Joe' , 'Acct');
INSERT INTO Personnel VALUES('Lisa' , 'DP');
INSERT INTO Personnel VALUES('Helen', 'DP');
INSERT INTO Personnel VALUES('Fonda', 'DP');
ちなみに、Oracle は集約関数の入れ子を2レベルまで認めているので、次のような一つのクエリで書けます。
SELECT AVG(COUNT(*)) AS avg_cnt
FROM Personnel
GROUP BY dept_id;
avg_cnt
-------
2.5
便利な機能ではあります。ただし標準違反の独自拡張なので、互換性は一切ありません。
第53問 テーブルを列で分解する
一種の行間比較なんですが、ちょっと風変わりな問題です。どういうアプリケーションで使うテーブルだったんでしょうね?
サンプルデータ
CREATE TABLE Foobar
(lvl INTEGER NOT NULL PRIMARY KEY,
color VARCHAR(10),
length INTEGER,
width INTEGER,
hgt INTEGER);
INSERT INTO Foobar VALUES (1, 'RED', 8, 10, 12);
INSERT INTO Foobar VALUES (2, NULL, NULL, NULL, 20);
INSERT INTO Foobar VALUES (3, NULL, 9, 82, 25);
INSERT INTO Foobar VALUES (4, 'BLUE', NULL, 67, NULL);
INSERT INTO Foobar VALUES (5, 'GRAY', NULL, NULL, NULL);
いずれの解答も見事なものですが、ここではセルコのその2のコードを取り上げましょう。
レベル1〜5までの一行ごとにテーブルを分解するために、テーブルを5つ使った自己結合を用います。WHERE句の 「lvl = n」の条件によって、F1 〜 F5 のテーブルはどれも一行だけになることが保証されます(lvl は主キーだから)。そうすると、あたかも F1 〜 F5 のテーブル群を、一行だけの大きな一つのテーブルとして見立てることが可能になるわけです。その意味で、この問題は行列変換の一種でもあります。後は、COALESCE 関数で底から順に列を走査するだけです。実にエレガントな解決ではありませんか。
参考:
第54問 隠れた重複行
この問題で「重複行」と呼ばれているのは、問題文にも書いてあるように、一般的な意味での重複ではなく、「5列のうちの任意の2列」について重複する行のことです。「弱い重複」と名づけておきましょう。
サンプルデータ
CREATE TABLE Customers
(custnbr INTEGER,
last_name CHAR(10),
first_name CHAR(10),
street_address INTEGER,
city_name CHAR(10),
state_code INTEGER,
phone_nbr INTEGER);
INSERT INTO Customers VALUES(1, 'Smith', 'Mike', 1, 'New York', 1, 1);
INSERT INTO Customers VALUES(2, 'Darwin', 'Ken', 1, 'New York', 0, 5);
INSERT INTO Customers VALUES(3, 'Haxley', 'Kate', 2, 'Chicago', 1, 10);
INSERT INTO Customers VALUES(4, 'Darwin', 'John', 9, 'Los', 0, 5);
INSERT INTO Customers VALUES(5, 'Haxley', 'Mick', 2, 'Keswick', 0, 10);
上のサンプルデータだと、重複行と見なされるのは city_name と phone_nbr が同じ Ken と John 、および street_address と phone_nbr が同じ Kate と Mick です。
答え2は、重複行は選択できるのですが、各行が「誰と」重複しているのかまでは分からないところが少し難点です。重複をペアで出力するには、私の考えた次の改良版を使います。
SELECT C0.custnbr, C1.custnbr
FROM Customers AS C0, Customers AS C1
WHERE C0.last_name = C1.last_name
AND C0.custnbr < C1.custnbr
AND (CASE WHEN C0.first_name = C1.first_name
THEN 1 ELSE 0 END)
+ (CASE WHEN C0.street_address = C1.street_address
THEN 1 ELSE 0 END)
+ (CASE WHEN C0.city_name = C1.city_name
THEN 1 ELSE 0 END)
+ (CASE WHEN C0.state_code = C1.state_code
THEN 1 ELSE 0 END)
+ (CASE WHEN C0.phone_nbr = C1.phone_nbr
THEN 1 ELSE 0 END) >= 2;
custnbr custnbr
------- -------
2 4
3 5
CASE式の便利さが光りますが、この問題も実は、自己結合を使って一種の行列変換を行っているという点で、前問と同じ構造をもっています。気付きましたか?
第55問 競走馬の入賞回数
おなじみの行列変換の問題です。今度は外部結合で一種のクロス表を作ることが目的です。
サンプルデータ
CREATE TABLE RacingResults
(track_id CHAR(3) NOT NULL,
race_date DATE NOT NULL,
race_nbr INTEGER NOT NULL,
win_name CHAR(30) NOT NULL,
place_name CHAR(30) NOT NULL,
show_name CHAR(30) NOT NULL,
PRIMARY KEY (track_id, race_date, race_nbr));
CREATE TABLE HorseNames
(horse CHAR(30) NOT NULL PRIMARY KEY);
INSERT INTO RacingResults VALUES(1, '2007-05-01', 1, 'A', 'B', 'C');
INSERT INTO RacingResults VALUES(1, '2007-05-01', 2, 'E', 'F', 'P');
INSERT INTO RacingResults VALUES(1, '2007-05-02', 1, 'B', 'C', 'A');
INSERT INTO RacingResults VALUES(2, '2007-05-02', 1, 'O', 'P', 'Q');
INSERT INTO RacingResults VALUES(2, '2007-05-02', 2, 'A', 'P', 'Q');
INSERT INTO HorseNames VALUES('A');
INSERT INTO HorseNames VALUES('B');
INSERT INTO HorseNames VALUES('C');
INSERT INTO HorseNames VALUES('D');
INSERT INTO HorseNames VALUES('E');
INSERT INTO HorseNames VALUES('F');
INSERT INTO HorseNames VALUES('O');
INSERT INTO HorseNames VALUES('P');
INSERT INTO HorseNames VALUES('Q');
答え2のクエリは、内部結合を使っているので、一度も入賞していない馬 D は、結果に現れません。もし D も結果に含めたいなら、本文にもあるとおり外部結合を使います。ただし、その場合、注意が必要なのは COUNT(*) を COUNT(R1.track_id) などに変える必要があることです。もし COUNT(*) をそのまま使うと、一度も入賞していない D についても入賞回数が「1」になってしまいます。これは、COUNT(*) がとにかく行数を数えてしまうからです。
SELECT H1.horse, COUNT(R1.track_id)
FROM HorseNames AS H1 LEFT OUTER JOIN RacingResults AS R1
ON H1.horse IN (R1.win_name, R1.place_name, R1.show_name)
GROUP BY H1.horse;
horse count
----- -----
A 3
B 2
C 2
D 0 --入賞0回の D も現れる
E 1
F 1
O 1
P 3
Q 2
なお、答え3の場合には、この心配はありません。スカラ・サブクエリ内の結合は結局、内部結合なので、入賞経験のない馬の行は現れないからです。
第56問 ホテルの部屋番号
連番による更新という、これも実務でたまに見かける興味深い問題です。Hotel テーブルは、問題文では外部キーを持っていましたが、特に重要ではないので以下のサンプルでは省略します。
サンプルデータ
CREATE TABLE Hotel
(floor_nbr INTEGER NOT NULL,
room_nbr INTEGER);
INSERT INTO Hotel VALUES(1, NULL);
INSERT INTO Hotel VALUES(1, NULL);
INSERT INTO Hotel VALUES(1, NULL);
INSERT INTO Hotel VALUES(2, NULL);
INSERT INTO Hotel VALUES(2, NULL);
INSERT INTO Hotel VALUES(3, NULL);
答え1,2は、いずれもちょっと面倒な方法ですし、実装依存の危険もあります。答え3は大変エレガントですし、標準 SQL でもあるのですが、次の二つの条件を満たす環境でしか使えません。
- OLAP 関数を SET 句で使える。
- OVER句に ORDER BY の指定が必要ない。
私が確認した限り、この二つの条件を満たすのは DB2 だけでした。Oracle、SQLServer ではエラーになります。他の DB でこれを実現するには、もう少し手の込んだ方法が必要になります。私がおすすめするのは、次のような方法です。
まず初期データの登録時点で、room_nbr には NULL ではなく適当な通し連番を振っておくようにします。これはどの DB でも簡単にできます。シーケンス・オブジェクトを使ってもいいですし、単純に次のように関数を組み込んでもいいでしょう。こうすれば、テーブル定義にも最初から主キーを付けておけるので、なおよしです。
--Oracle
INSERT INTO Hotel VALUES(1, COALESCE(MAX(room_nbr), 0) +1);
INSERT INTO Hotel VALUES(1, COALESCE(MAX(room_nbr), 0) +1);
INSERT INTO Hotel VALUES(1, COALESCE(MAX(room_nbr), 0) +1);
INSERT INTO Hotel VALUES(2, COALESCE(MAX(room_nbr), 0) +1);
INSERT INTO Hotel VALUES(2, COALESCE(MAX(room_nbr), 0) +1);
INSERT INTO Hotel VALUES(3, COALESCE(MAX(room_nbr), 0) +1);
--PostgreSQL
INSERT INTO Hotel VALUES(1, (SELECT COALESCE(MAX(room_nbr), 0) +1 FROM hotel));
INSERT INTO Hotel VALUES(1, (SELECT COALESCE(MAX(room_nbr), 0) +1 FROM hotel));
INSERT INTO Hotel VALUES(1, (SELECT COALESCE(MAX(room_nbr), 0) +1 FROM hotel));
INSERT INTO Hotel VALUES(2, (SELECT COALESCE(MAX(room_nbr), 0) +1 FROM hotel));
INSERT INTO Hotel VALUES(2, (SELECT COALESCE(MAX(room_nbr), 0) +1 FROM hotel));
INSERT INTO Hotel VALUES(3, (SELECT COALESCE(MAX(room_nbr), 0) +1 FROM hotel));
floor_nbr room_nbr
--------- --------
1 1
1 2
1 3
2 4
2 5
3 6
そうしたら、後は「第4問 入館証」の答え2の連番リセットの UPDATE 文と同じ要領です。
UPDATE Hotel
SET room_nbr
= (floor_nbr * 100)
+ (SELECT COUNT(*)
FROM Hotel H1
WHERE Hotel.floor_nbr = H1.floor_nbr
AND Hotel.room_nbr >= H1.room_nbr);
floor_nbr room_nbr
--------- --------
1 101
1 102
1 103
2 201
2 202
3 301
これなら実装非依存でびしっと連番を割り振れます。しかもフロアが変わったらまた開始が1にリセットされてグー。
第57問 欠番探しバージョン1
これは非常に興味深い問題です。というのは、実用的であると同時に、SQL の集合指向言語としての特性が非常に前面に出た見事な解法をとるからです。
サンプルデータ
CREATE TABLE Numbers (seq INTEGER NOT NULL PRIMARY KEY);
INSERT INTO Numbers VALUES (2);
INSERT INTO Numbers VALUES (3);
INSERT INTO Numbers VALUES (5);
INSERT INTO Numbers VALUES (7);
INSERT INTO Numbers VALUES (8);
INSERT INTO Numbers VALUES (14);
INSERT INTO Numbers VALUES (20);
まず、本問および次問を解くにあたって最も基礎的な技術が、COUNT(*) と MAX(seq) の一致をテストすることで、連番の歯抜けをチェックする、というものです。なぜこれで欠番チェックが可能かと言えば、COUNT(*) の返す行数と、MAX(seq) の返す連番の最大値が一致する条件は、まさに「連番に歯抜けがない」だからです。もし連番に歯抜けがあれば、必ず COUNT(*) の方が小さくなります。集合論的な言い方をすれば、これは、自然数の集合と連番の集合の間の一対一対応をテストしているのです。
これがすぐれ集合指向的な発想であることは、同じ問題を手続き型言語とファイルを使って解くことを考えれば分かります。その場合、欠番チェックのアルゴリズムは次のようになるでしょう。
- 欠番の昇順か降順にソートする。
- ループさせて、1行ずつ次の行と連番を比較する。
この単純な手順の中にも、手続き型言語とファイルシステムの特徴が浮き彫りになっています。それは、ファイルのレコードは順序を持ち、それを扱うために、言語はソートを行うということです。翻って、リレーショナル・データベースのテーブルは、行の順序を持ちませんし、必然的にソートも行いません。その代わり、SQL では行の集合全体を一つの基礎的単位と見なし、その性質を調べるのです。
なお、答え2のギャップの最小値を見つけるクエリは、もっと条件を簡略化できます(詳しくは参考資料を参照)。また、答え3で、セルコは「EXCEPT ALL」を使っています。これは、Sequence テーブルも Numbers テーブルも一意でソートの必要がないことを考えれば、適切なパフォーマンス・チューニングですが、まだこのオプションを使えない DB も多いでしょう(現在のところ、使えるのは DB2 と PostgreSQL だけです)。そういう場合は、普通に「EXCEPT」に置き換えてください。
参考:
第58問 欠番探しバージョン2
同じく欠番チェックですが、前問がテーブル全体を一つの集合と見なしていたのに対し、今度は buyer_name をキーとして区別される複数の部分集合の中で欠番を探すことです。
サンプルデータ
CREATE TABLE Tickets
(buyer_name CHAR(5) NOT NULL,
ticket_nbr INTEGER DEFAULT 1 NOT NULL
CHECK (ticket_nbr > 0),
PRIMARY KEY (buyer_name, ticket_nbr));
INSERT INTO Tickets VALUES ('a', 2);
INSERT INTO Tickets VALUES ('a', 3);
INSERT INTO Tickets VALUES ('a', 4);
INSERT INTO Tickets VALUES ('b', 4);
INSERT INTO Tickets VALUES ('c', 1);
INSERT INTO Tickets VALUES ('c', 2);
INSERT INTO Tickets VALUES ('c', 3);
INSERT INTO Tickets VALUES ('c', 4);
INSERT INTO Tickets VALUES ('c', 5);
INSERT INTO Tickets VALUES ('d', 1);
INSERT INTO Tickets VALUES ('d', 6);
INSERT INTO Tickets VALUES ('d', 7);
INSERT INTO Tickets VALUES ('d', 9);
INSERT INTO Tickets VALUES ('e', 10);
答え1や3の実行結果は、次のようになります。
--答え3
SELECT DISTINCT T2.buyer_name, T2.ticket_nbr
FROM (SELECT T1.buyer_name, S1.seq AS ticket_nbr
FROM (SELECT buyer_name, MAX(ticket_nbr)
FROM Tickets
GROUP BY buyer_name) AS T1(buyer_name, max_nbr),
Sequence AS S1
WHERE S1.seq <= max_nbr) AS T2
LEFT OUTER JOIN Tickets AS T3
ON T2.buyer_name = T3.buyer_name
AND T2.ticket_nbr = T3.ticket_nbr
WHERE T3.ticket_nbr IS NULL;
buyer_name ticket_nbr
---------- ---------
a 1
b 1
b 2
b 3
d 2
d 3
d 4
d 5
d 8
e 1
e 2
e 3
e 4
e 5
e 6
e 7
e 8
e 9
第59問 期間を結合する
「第3問 忙しい麻酔医」などでも見たように、SQL で期間を扱うのはけっこうしんどい話です。OVERLPAS 述語が一般的に実装されればもっと簡単に解決できるようになるでしょうが、BETWEEN だけでやろうとすると大変。
サンプルデータ
CREATE TABLE Timesheets
(task_id CHAR(10) NOT NULL PRIMARY KEY,
start_date DATE NOT NULL,
end_date DATE NOT NULL,
CHECK(start_date <= end_date));
INSERT INTO Timesheets VALUES (1, '1997-01-01', '1997-01-03');
INSERT INTO Timesheets VALUES (2, '1997-01-02', '1997-01-04');
INSERT INTO Timesheets VALUES (3, '1997-01-04', '1997-01-05');
INSERT INTO Timesheets VALUES (4, '1997-01-06', '1997-01-09');
INSERT INTO Timesheets VALUES (5, '1997-01-09', '1997-01-09');
INSERT INTO Timesheets VALUES (6, '1997-01-09', '1997-01-09');
INSERT INTO Timesheets VALUES (7, '1997-01-12', '1997-01-15');
INSERT INTO Timesheets VALUES (8, '1997-01-13', '1997-01-14');
INSERT INTO Timesheets VALUES (9, '1997-01-14', '1997-01-14');
INSERT INTO Timesheets VALUES (10, '1997-01-17', '1997-01-17');
私はこの問題について以前に詳しい解説を書いていますので、以下を参照。
参考:
第60問 バーコード
ピュア SQL に力点を置く本書の中では珍しくプロシージャを取り上げます。難しい問題はすぐプロシージャ(あるいはホスト言語)で解決しようとする SQL に不慣れな手続き型どっぷりプログラマには耳が痛いと同時に勉強になる回でもあります。
この問題に関しては特にサンプルデータというのはありませんが、答え2と3のユーザ定義関数を Oracle の PL/SQL に変換したものを載せておきましょう。
--答え2:PL/SQL版
CREATE OR REPLACE FUNCTION Barcode_CheckSum(barcode IN CHAR) RETURN INTEGER
AS
check_sum INTEGER := 0;
BEGIN
IF REGEXP_LIKE(barcode, '[^0-9]') THEN
RETURN -1;
ELSIF LENGTH(barcode) > 12 THEN
RETURN -2;
ELSE
SELECT ABS(MOD(SUM(CAST(SUBSTR(barcode, seq, 1) AS INTEGER)
* CASE MOD(seq, 2)
WHEN 0 THEN 1
ELSE -1 END), 10)) INTO check_sum
FROM Sequence
WHERE seq <= 12;
RETURN check_sum;
END IF;
END;
/
SELECT Barcode_CheckSum('283723281122') AS check_sum
FROM dual;
check_sum
---------
7
SELECT Barcode_CheckSum('2837232r1122') AS check_sum
FROM dual;
check_sum
---------
-1
SELECT Barcode_CheckSum('2837232811229') AS check_sum
FROM dual;
check_sum
---------
-2
注意すべき点としては、Oracleで正規表現の関数 REGEXP_LIKE が使えるのは 10g からであること、および、Oracle では引数の型で文字列長までは指定できないので、13文字以上の文字列を受け取ってもオーバーフローエラーにできないことです。その代わりに、コード内で13文字以上の場合は -2 を返す処理を追加しています。
答え3は次のようになります。
--答え3:PL/SQL版
CREATE OR REPLACE FUNCTION Barcode_CheckSum(barcode IN CHAR) RETURN INTEGER
AS
check_sum INTEGER := 0;
BEGIN
SELECT ABS(MOD(SUM(CAST(SUBSTR(barcode, seq, 1) AS INTEGER)
* CASE MOD(seq, 2)
WHEN 0 THEN 1
ELSE -1 END), 10)) INTO check_sum
FROM Sequence
WHERE seq <= 12
AND NOT REGEXP_LIKE(barcode, '[^0-9]');
RETURN check_sum;
END;
/
SELECT Barcode_CheckSum('283723281122') AS check_sum
FROM dual;
check_sum
---------
7
SELECT Barcode_CheckSum('2837232r1122') AS check_sum
FROM dual;
check_sum
---------
NULL
SELECT Barcode_CheckSum('2837232811229') AS check_sum
FROM dual;
check_sum
---------
NULL
今度は、数字以外の文字が入力されたり、13桁以上の場合は NULL を返します。確かにこの方が一つのクエリに凝縮できて簡潔なんですが、個人的には答え2のように、エラーの発生原因に応じて細かくエラーコードを指定できるほうが好きです。
第61問 文字列をソートする
これも小問ながら、発想の転換を要する洒落た問題です。テーマはさっきと同じで、手続き型から宣言型へのパラダイム・シフトに慣れることです。ここでは、答え3のコードを使ったビューを紹介しましょう。
サンプルデータ
CREATE TABLE SortMeFast
(unsorted_string CHAR(7) NOT NULL PRIMARY KEY);
INSERT INTO SortMeFast VALUES('CABBDBC');
--PostgreSQL
CREATE VIEW SortedStrings (sortedstring)
AS SELECT REPEAT('A', (LENGTH(unsorted_string) -
LENGTH(REPLACE(unsorted_string, 'A', '')))) ||
REPEAT('B', (LENGTH(unsorted_string) -
LENGTH(REPLACE(unsorted_string, 'B', '')))) ||
REPEAT('C', (LENGTH(unsorted_string) -
LENGTH(REPLACE(unsorted_string, 'C', '')))) ||
REPEAT('D', (LENGTH(unsorted_string) -
LENGTH(REPLACE(unsorted_string, 'D', ''))))
FROM SortMeFast;
--MySQL
CREATE VIEW SortedStrings (sortedstring)
AS SELECT CONCAT(REPEAT('A', (LENGTH(unsorted_string) -
LENGTH(REPLACE(unsorted_string, 'A', '')))),
CONCAT(REPEAT('B', (LENGTH(unsorted_string) -
LENGTH(REPLACE(unsorted_string, 'B', '')))),
CONCAT(REPEAT('C', (LENGTH(unsorted_string) -
LENGTH(REPLACE(unsorted_string, 'C', '')))),
REPEAT('D', (LENGTH(unsorted_string) -
LENGTH(REPLACE(unsorted_string, 'D', '')))))))
FROM SortMeFast;
sortedstring
------------
ABBBCCD
MySQL は文字列連結に CONCAT を使わねばならないのが不便です。ちょっとコードが見づらくなる。ところで、Oracle のように REPEAT や REPLICATE みたいな文字をコピーする関数がない場合、どうやって書けばいいんでしょうね? 私にゃよく分からん。誰か考えてください。
参考:
第62問 レポートの整形
いやあ、いい具合に狂ってますね。誰だこんなコード考えたの。セルコも前書きで釘刺してますけど、実務でこれ使っちゃダメですからね。フォーマットの整形は可能な限りフロント・エンドのプログラムで行う、というのが基本です。この問題はあくまで一種の「オトナの遊び」なので、そこんとこよろしく。
サンプルデータ
CREATE TABLE Names
(name VARCHAR(15) NOT NULL PRIMARY KEY);
INSERT INTO Names VALUES ('Al');
INSERT INTO Names VALUES ('Ben');
INSERT INTO Names VALUES ('Charlie');
INSERT INTO Names VALUES ('David');
INSERT INTO Names VALUES ('Ed');
INSERT INTO Names VALUES ('Frank');
INSERT INTO Names VALUES ('Greg');
INSERT INTO Names VALUES ('Howard');
INSERT INTO Names VALUES ('Ida');
INSERT INTO Names VALUES ('Joe');
INSERT INTO Names VALUES ('Ken');
INSERT INTO Names VALUES ('Larry');
INSERT INTO Names VALUES ('Mike');
INSERT INTO Names VALUES ('Neal');
しかし何でしょうね、解答者たちの SQL に賭けるこの不条理な情熱は・・・。
第63問 連続的なグルーピング
結合条件で相関サブクエリを使うというのは、最初に見るとびっくりするかもしれませんが、実はけっこう使い勝手のよい技術です。外部結合の場合も、基本的には内部結合の場合と同じように考えてかまいません。
サンプルデータ
CREATE TABLE T
(num INTEGER NOT NULL PRIMARY KEY,
data CHAR(1) NOT NULL);
INSERT INTO T VALUES (1, 'a');
INSERT INTO T VALUES (2, 'a');
INSERT INTO T VALUES (3, 'b');
INSERT INTO T VALUES (6, 'b');
INSERT INTO T VALUES (8, 'a');
なお、Oracle では、外部結合の結合条件に必ずマスタテーブルの列を使わねばならない、という妙な不文律があるようで、答え1は次のように本当は不要な条件を一つ追加してやらないと正しい結果を返しません。
SELECT MIN(T1.num) AS low,
MAX(T1.num) AS high,
T1.data
FROM T T1
LEFT OUTER JOIN T T2
ON T1.num < T2.num --論理的には不要な条件
AND T2.num
= (SELECT MIN(num)
FROM T
WHERE num > T1.num
AND data <> T1.data)
GROUP BY T1.data, T2.num;
low high data
--- ---- ----
1 2 a
3 6 b
8 8 a
またこの問題は、つまるところ行間比較なので、OLAP 関数を使った解法もあるでしょう。皆さんも考えてみてください。
第64問 ボックス
セルコも本文で言うように、この問題は面白い。言うならば、「n次元の関係除算」となるでしょうか。座標空間でイメージできるのは3次元までですが、4次元以上でもこのクエリは問題なく拡張できます。
サンプルデータ
CREATE TABLE Boxes
(box_id CHAR(1) NOT NULL,
dim CHAR(1) NOT NULL,
PRIMARY KEY (box_id, dim),
low INTEGER NOT NULL,
high INTEGER NOT NULL);
INSERT INTO Boxes VALUES('A', 'x',0,2);
INSERT INTO Boxes VALUES('A', 'y',0,2);
INSERT INTO Boxes VALUES('A', 'z',0,2);
INSERT INTO Boxes VALUES('B', 'x',1,3);
INSERT INTO Boxes VALUES('B', 'y',1,3);
INSERT INTO Boxes VALUES('B', 'z',1,3);
INSERT INTO Boxes VALUES('C', 'x',10,12);
INSERT INTO Boxes VALUES('C', 'y',0,4);
INSERT INTO Boxes VALUES('C', 'z',0,100);
各次元ごとに線分の重複を調べて、全部の次元で重複しているなら、ボックス同士は共有部分を持つ、ということです。言ってみればこれは、「次元についての関係除算」というところです。
参考:
第65問 製品の対象年齢の範囲
この問題の面白いところは、一レコードで年齢範囲をカバーできない製品であっても、複数レコードが部分的にカバーしあって、全体として要求された年齢範囲をカバーできたなら、「合わせ技一本」と見なす、というところです。
サンプルデータ
CREATE TABLE PriceByAge
(product_id CHAR(10) NOT NULL,
low_age INTEGER NOT NULL,
high_age INTEGER NOT NULL,
CHECK (low_age < high_age),
product_price DECIMAL (12,4) NOT NULL,
PRIMARY KEY (product_id, low_age));
--Product1は×、Product2は○
INSERT INTO PriceByAge VALUES ('Product1', 5, 15, 20.00);
INSERT INTO PriceByAge VALUES ('Product1', 16, 60, 18.00);
INSERT INTO PriceByAge VALUES ('Product1', 65, 150, 17.00);
INSERT INTO PriceByAge VALUES ('Product2', 1, 5, 20.00);
INSERT INTO PriceByAge VALUES ('Product2', 6, 70, 25.00);
INSERT INTO PriceByAge VALUES ('Product2', 71, 150, 40.00);
本文では、連番テーブルを使った解法を紹介しています。「第48問 非グループ化」でもそうですが、セルコは連番テーブルが大好きです。
なお、この問題には一つ前提があって、行同士で年齢範囲に重複がないことが必要です。重複がある場合はもっと難しくなります。
では、一つ簡単な演習問題を出しておきましょう。答え2のクエリを「20〜55歳」みたいな中途半端な年齢範囲にも適用できるように変更してください。
第66問 数独パズル
ちょっとお遊びの入った問題。サンプルデータを作るには、1 〜 9 の連番を持つ Digits テーブルが必要になります。
サンプルデータ
CREATE TABLE SudokuGrid
(i INTEGER NOT NULL
CHECK (i BETWEEN 1 AND 9),
j INTEGER NOT NULL
CHECK (j BETWEEN 1 AND 9),
val INTEGER NOT NULL
CHECK (val BETWEEN 1 AND 9),
region_nbr INTEGER NOT NULL,
PRIMARY KEY (i, j, val));
CREATE TABLE Digits
(digit INTEGER PRIMARY KEY);
INSERT INTO Digits VALUES (1);
INSERT INTO Digits VALUES (2);
INSERT INTO Digits VALUES (3);
INSERT INTO Digits VALUES (4);
INSERT INTO Digits VALUES (5);
INSERT INTO Digits VALUES (6);
INSERT INTO Digits VALUES (7);
INSERT INTO Digits VALUES (8);
INSERT INTO Digits VALUES (9);
本書で紹介されている方法は、非常に簡単なバージョンにだけ対応したものです。これをもっと一般的に拡張するには、プロシージャを使う必要があります。
参考:
第67問 安定な結婚
多分、情報工学を専攻した人は、この問題を必ず授業で習ったでしょう。この手の組み合わせ問題は、SQL の苦手とするところです。解けることは解けるのですが、SQL は一度可能な組み合わせを網羅した後に、不要な組み合わせを排除する、という実行順序をとるため、パフォーマンスが大変悪くなります(パズルとしては非常に面白いのだけど)。本文に完全なテーブル定義と INSERT 文がありますし、非常にコードが長いので、この問題についてはサンプルデータは省略します。
ちなみに、答え3の文字列中にワイルドカード( _ )を埋め込む方法は、Oracle ではうまくいきますが、DB2 ではワイルドカードとして認識してくれません。
第68問 バスを待ちながら
私たちは普通、SQL の問題を考えるとき、ついついアクロバティックな SELECT 文を書く方向に流れがちです。でも本当は、SELECT 文があまりに複雑になるケースの9割は、テーブル設計が悪いのです。従って最も効果的かつ根本的な解決は、テーブル定義を変えることにあります。もっとも、「もうずっとこのテーブルでやってきてるから」とか「お前にそんな権限はない」とか、色々と非論理的な理由によってテーブル定義を変えることは現実に難しい場合が多いのですが・・・。
セルコは、本書の中でもしばしばテーブル定義そのものを変える解法を示唆していますが、この問題はその方法を意識して前面に出したものです。計算ではなく、テーブルを参照することで答えを求める考え方を、セルコは「テーブル駆動型」と呼んでいます。
サンプルデータ
CREATE TABLE Schedule
(route_nbr INTEGER NOT NULL,
depart_time TIMESTAMP NOT NULL,
arrive_time TIMESTAMP NOT NULL,
CHECK (depart_time < arrive_time),
PRIMARY KEY (route_nbr, depart_time));
INSERT INTO Schedule VALUES (3, '2006-02-09 10:00', '2006-02-09 14:00');
INSERT INTO Schedule VALUES (4, '2006-02-09 16:00', '2006-02-09 17:00');
INSERT INTO Schedule VALUES (5, '2006-02-09 18:00', '2006-02-09 19:00');
INSERT INTO Schedule VALUES (6, '2006-02-09 20:00', '2006-02-09 21:00');
INSERT INTO Schedule VALUES (7, '2006-02-09 11:00', '2006-02-09 13:00');
INSERT INTO Schedule VALUES (8, '2006-02-09 15:00', '2006-02-09 16:00');
INSERT INTO Schedule VALUES (9, '2006-02-09 18:00', '2006-02-09 20:00');
CREATE TABLE Schedule
(route_nbr INTEGER NOT NULL,
wait_time TIMESTAMP NOT NULL,
depart_time TIMESTAMP NOT NULL,
arrive_time TIMESTAMP NOT NULL,
CHECK (depart_time < arrive_time),
PRIMARY KEY (route_nbr, depart_time));
INSERT INTO Schedule VALUES (3, '2006-02-09 00:00', '2006-02-09 10:00', '2006-02-09 14:00');
INSERT INTO Schedule VALUES (7, '2006-02-09 10:00', '2006-02-09 11:00', '2006-02-09 13:00');
INSERT INTO Schedule VALUES (8, '2006-02-09 11:00', '2006-02-09 15:00', '2006-02-09 16:00');
INSERT INTO Schedule VALUES (4, '2006-02-09 15:00', '2006-02-09 16:00', '2006-02-09 17:00');
INSERT INTO Schedule VALUES (5, '2006-02-09 16:00', '2006-02-09 18:00', '2006-02-09 19:00');
INSERT INTO Schedule VALUES (9, '2006-02-09 16:00', '2006-02-09 18:00', '2006-02-09 20:00');
INSERT INTO Schedule VALUES (6, '2006-02-09 18:00', '2006-02-09 20:00', '2006-02-09 21:00');
「第37問 移動平均」や「第38問 記録の更新」でも問題になりましたが、この問題の wait_time 列もやはり計算列です。従って、理想的にはテーブルに持たないことが望ましいとされます。しかし、実際にはクエリの複雑さや実行速度の観点から、このような冗長な列を持つほうが現実的な解決であることがままあるのも事実です。
参考:
第69問 後入れ先出しと先入れ先出し
これは部分和問題という計算複雑性理論の分野の問題の一つです。いかめしい名前ですが、意味は簡単で、幾つかの数の集合が与えられたときに、足すと特定の数になるような部分集合が存在するか、ということです。例えば {1, 2, 3, 4, 5} という集合が与えられたとき、足して 7 になる組み合わせは存在するか? ということです(答え:存在する。{1, 2, 4} や {2, 5} がそう)。
サンプルデータ
CREATE TABLE WidgetInventory
(receipt_nbr INTEGER NOT NULL PRIMARY KEY,
purchase_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP NOT NULL,
qty_on_hand INTEGER NOT NULL
CHECK (qty_on_hand >= 0),
unit_price DECIMAL (12,4) NOT NULL);
INSERT INTO WidgetInventory VALUES(1, '2005-08-01', 15, 10.00);
INSERT INTO WidgetInventory VALUES(2, '2005-08-02', 25, 12.00);
INSERT INTO WidgetInventory VALUES(3, '2005-08-03', 40, 13.00);
INSERT INTO WidgetInventory VALUES(4, '2005-08-04', 35, 12.00);
INSERT INTO WidgetInventory VALUES(5, '2005-08-05', 45, 10.00);
第70問 株価の動向
これまでも何度も出てきた行間比較の良問です。ticker_sym というのが株の銘柄を表します。答え2の INSERT 文で三日分のデータを追加してみましょう。ただし、順番を間違えて最後に2日を間に挿入する形にします。
サンプルデータ
CREATE TABLE StockHistory
(ticker_sym CHAR(5) NOT NULL,
sale_date DATE DEFAULT CURRENT_DATE NOT NULL,
closing_price DECIMAL (10,4) NOT NULL,
trend INTEGER DEFAULT 0 NOT NULL
CHECK(trend IN(-1, 0, 1)),
PRIMARY KEY (ticker_sym, sale_date));
--4月1日(trend=0)
INSERT INTO StockHistory (ticker_sym, sale_date, closing_price, trend)
VALUES ('XXX', '2007-04-01', 100,
COALESCE(SIGN(100
- (SELECT H1.closing_price
FROM StockHistory H1
WHERE H1.ticker_sym = StockHistory.ticker_sym
AND H1.sale_date
= (SELECT MAX(sale_date)
FROM StockHistory H2
WHERE H2.ticker_sym = 'XXX'
AND H2.sale_date < '2007-04-01'))), 0));
--4月3日(trend=1)
INSERT INTO StockHistory (ticker_sym, sale_date, closing_price, trend)
VALUES ('XXX', '2007-04-03', 200,
COALESCE(SIGN(200
- (SELECT H1.closing_price
FROM StockHistory H1
WHERE H1.ticker_sym = StockHistory.ticker_sym
AND H1.sale_date
= (SELECT MAX(sale_date)
FROM StockHistory H2
WHERE H2.ticker_sym = 'XXX'
AND H2.sale_date < '2007-04-03'))), 0));
--4月2日(trend=-1)
INSERT INTO StockHistory (ticker_sym, sale_date, closing_price, trend)
VALUES ('XXX', '2007-04-02',300,
COALESCE(SIGN(300
- (SELECT H1.closing_price
FROM StockHistory H1
WHERE H1.ticker_sym = StockHistory.ticker_sym
AND H1.sale_date
= (SELECT MAX(sale_date)
FROM StockHistory H2
WHERE H2.ticker_sym = 'XXX'
AND H2.sale_date < '2007-04-02'))), 0));
--3日の trend が再計算されない。
ticke sale_dat closing_price trend
----- -------- ------------- -----
XXX 07-04-01 100 0
XXX 07-04-03 200 1
XXX 07-04-02 50 1
この方法では、当たり前ですが、既に追加されていた4月3日の trend は再計算されません。そのため、正しくは2日が追加されたことで「1 → -1」へ変更されるべきところが、1 のままになっています。これを修正するには、答え3の UPDATE を用いるか、ビューで表現することです。
なお、この問題の答え3は、書籍のコードに間違いがあります。以下に修正版のコードとサンプルデータを示します。
INSERT INTO StockHistory VALUES(1, '2007-04-01', 100);
INSERT INTO StockHistory VALUES(1, '2007-04-02', 200);
INSERT INTO StockHistory VALUES(1, '2007-04-03', 199);
INSERT INTO StockHistory VALUES(1, '2007-04-04', 199);
INSERT INTO StockHistory VALUES(2, '2006-10-10', 10);
INSERT INTO StockHistory VALUES(2, '2007-04-14', 20);
INSERT INTO StockHistory VALUES(2, '2007-04-20', 5);
--答え3:修正版
SELECT ticker_sym, sale_date, closing_price,
SIGN(closing_price -
(SELECT closing_price
FROM StockHistory H2
WHERE H1.ticker_sym = H2.ticker_sym
AND H2.sale_date = (SELECT MAX(H3.sale_date)
FROM StockHistory H3
WHERE H2.ticker_sym = H3.ticker_sym
AND H3.sale_date < H1.sale_date))) AS trend
FROM StockHistory H1;
ticker_sym sale_date closing_price trend
---------- ----------- --------------- ------
1 2007-04-01 100.0000
1 2007-04-02 200.0000 1
1 2007-04-03 199.0000 -1
1 2007-04-04 199.0000 0
2 2006-10-10 10.0000
2 2007-04-14 20.0000 1
2 2007-04-20 5.0000 -1
この問題は、『プログラマのためのSQL 第2版の』「23.5.2 累積差」でも扱われている問題です。刊行前に修正するべきでしたが、見落としてしまいました。申し訳ありません。
第71問 計算
この問題、正直、本文読んだだけだととりとめなくて、何が言いたいのか要領をえないんですよね。恐らくこれは、自己結合を使った行列展開をさせたいのだと思います。その点で、15.現在の給料と昇給前の給料などに近いと思うと理解しやすいのではないでしょうか。
サンプルデータ
CREATE TABLE Foobar
(empl_id CHAR(6) NOT NULL, pin_nbr CHAR(5) NOT NULL,
empl_rcd INTEGER NOT NULL, calc_rslt_val INTEGER NOT NULL,
calc_adj_val INTEGER NOT NULL, unit_rslt_val INTEGER NOT NULL,
unit_adj_val INTEGER NOT NULL, PRIMARY KEY (empl_id, pin_nbr));
INSERT INTO Foobar VALUES('xxxxxx', '52636', 0, 10, 20, 30, 40);
INSERT INTO Foobar VALUES('xxxxxx', '52751', 0, 5, 6, 7, 8);
INSERT INTO Foobar VALUES('xxxxxx', '52768', 0, 20, 40, 60, 80);
答え2を実行すると、pin_nbr が 52636、52751、52768 の三行のレコードを、列に展開した結果が返ってきます。
--答え2
SELECT DISTINCT
SUM(F1.calc_rslt_val + F1.calc_adj_val) AS calc_1,
SUM(F1.unit_rslt_val + F1.unit_adj_val) AS unit_1,
SUM(f2.calc_rslt_val + f2.calc_adj_val) AS calc_2,
SUM(f2.unit_rslt_val + f2.unit_adj_val) AS unit_2,
SUM(f3.calc_rslt_val + f3.calc_adj_val) AS calc_3,
SUM(f3.unit_rslt_val + f3.unit_adj_val) AS unit_3
FROM Foobar F1, Foobar f2, Foobar f3
WHERE F1.empl_id = 'xxxxxx'
AND f2.empl_id = 'xxxxxx'
AND f3.empl_id = 'xxxxxx'
AND F1.empl_rcd = 0
AND F1.pin_nbr = '52636'
AND f2.pin_nbr = '52751'
AND f3.pin_nbr = '52768';
calc_1 unit_1 calc_2 unit_2 calc_3 unit_3
------ ------ ------ ------ ------ ------
30 70 11 15 60 140
一方、答え3は普通に行持ちの形に集約します。
--答え3
SELECT F1.pin_nbr,
SUM(F1.calc_rslt_val + F1.calc_adj_val) AS calc_val,
SUM(F1.unit_rslt_val + F1.unit_adj_val) AS unit_val
FROM Foobar F1
WHERE F1.empl_id = 'xxxxxx'
AND F1.empl_rcd = 0
AND F1.pin_nbr IN ('52636', '52751', '52768')
GROUP BY F1.pin_nbr;
pin_nbr calc_val unit_val
----- -------- --------
52636 30 70
52751 11 15
52768 60 140
どちらのロジックも、本書をここまで読んでこられた読者の皆さんには、もう説明の要はないでしょう。
第72問 サービスマンの予約管理
ここでは、他の問題のようなトリッキーなクエリには頼りません。むしろオーソドクスなテーブル設計のが主題です。華麗なテクニックが乱舞するのも悪くないですけど、こういう地味な、でも重要な練習がきっちり押さえられているのも、本書の名著たるゆえんです。
サンプルデータ
CREATE TABLE Clients
(client_id INTEGER NOT NULL PRIMARY KEY,
first_name VARCHAR(15) NOT NULL,
last_name VARCHAR(20) NOT NULL,
phone_nbr CHAR(15) NOT NULL,
phone_nbr_2 CHAR(15),
client_street VARCHAR(35) NOT NULL,
client_city_name VARCHAR(20) NOT NULL);
CREATE TABLE Personnel
(emp_id CHAR(9) NOT NULL PRIMARY KEY,
first_name VARCHAR(15) NOT NULL,
last_name VARCHAR(20) NOT NULL,
home_phome_nbr CHAR(15) NOT NULL,
cell_phone_nbr CHAR(15) NOT NULL,
street_addr VARCHAR(35) NOT NULL,
city_name VARCHAR(20) NOT NULL,
zip_code CHAR(5) NOT NULL);
CREATE TABLE ScheduledCalls
(client_id INTEGER NOT NULL
REFERENCES Clients (client_id),
scheduled_start_time TIMESTAMP NOT NULL,
scheduled_end_time TIMESTAMP NOT NULL,
CHECK (scheduled_start_time < scheduled_end_time),
emp_id CHAR(9) DEFAULT '{xxxxxxx}' NOT NULL
REFERENCES Personnel (emp_id),
PRIMARY KEY (client_id, emp_id, scheduled_start_time));
CREATE TABLE PersonnelSchedule
(emp_id CHAR(9) NOT NULL
REFERENCES Personnel(emp_id),
avail_start_time TIMESTAMP NOT NULL,
avail_end_time TIMESTAMP NOT NULL,
CHECK (avail_start_time < avail_end_time),
PRIMARY KEY (emp_id, avail_start_time));
--顧客テーブル
INSERT INTO Clients VALUES (1, '太郎', '田中', '03-5478-1243', '090-442-8765', '世田谷', '東京');
INSERT INTO Clients VALUES (2, '次郎', '鈴木', '03-9999-3487', '090-532-7543', '入谷', '東京');
INSERT INTO Clients VALUES (3, '三郎', '鎌田', '03-8765-3432', '090-223-1111', '中野', '東京');
--社員テーブル
INSERT INTO Personnel VALUES (1, 'aaa', 'bbb', '0', '0', 'hoge', 'hage', 'huga');
INSERT INTO Personnel VALUES (2, 'aaa', 'bbb', '0', '0', 'hoge', 'hage', 'huga');
INSERT INTO Personnel VALUES (3, 'aaa', 'bbb', '0', '0', 'hoge', 'hage', 'huga');
--予約テーブル
INSERT INTO ScheduledCalls VALUES(1, '2007-01-01:12:00', '2007-01-01:17:00', 1);
INSERT INTO ScheduledCalls VALUES(1, '2007-01-01:18:00', '2007-01-01:21:00', 2);
INSERT INTO ScheduledCalls VALUES(2, '2007-01-02:09:00', '2007-01-02:15:00', 3);
INSERT INTO ScheduledCalls VALUES(3, '2007-01-02:18:00', '2007-01-02:21:00', 2);
--対応可能な社員テーブル
INSERT INTO PersonnelSchedule VALUES (1, '2007-01-01:09:00', '2007-01-01:15:00');
INSERT INTO PersonnelSchedule VALUES (2, '2007-01-02:07:00', '2007-01-02:08:00');
INSERT INTO PersonnelSchedule VALUES (2, '2007-01-02:17:00', '2007-01-02:21:00');
INSERT INTO PersonnelSchedule VALUES (3, '2007-01-02:17:00', '2007-01-02:22:00');
解答のクエリのロジックに難しいところはありません。BETWEEN を結合条件に使っているのがうまいですね。社員がカバーできる予約は、(社員2, 顧客3)の組み合わせだけです。
--答え2
SELECT P.emp_id,
S.client_id,
S.scheduled_start_time,
S.scheduled_end_time
FROM ScheduledCalls S,
PersonnelSchedule P
WHERE S.emp_id = P.emp_id
AND P.emp_id <> '{xxxxxxx}'
AND S.scheduled_start_time BETWEEN P.avail_start_time AND P.avail_end_time
AND S.scheduled_end_time BETWEEN P.avail_start_time AND P.avail_end_time;
emp_id client_id scheduled_start_time scheduled_end_time
------ --------- -------------------- -------------------
2 3 20-07-01 02:18:00 20-07-01 02:21:00
顧客3は、社員2に18時から21時までを予約依頼しています。社員2も、17時から21時まで空いているので、対応可能です。ほかのペアを見ると、例えば、顧客2は社員3を9時から15時まで予約していますが、社員3は17−22時しか空いていないのでミスマッチです。
参考:
第73問 データのクリーニング
本文では触れられていませんが、質問者であるスタンジ君が扱っている「Staging」テーブルは、まず間違いなく擬似配列テーブルのたぐいです。列名からしてもうそんな雰囲気アリアリ。ゆえに根本的な問題は「そもそもテーブル設計が悪い」という点にあるのですが、しかしデータソース側への注文も付けられないスタンジ君の立場をかんがみるに、テーブル定義の変更を願い出る権限はもっとなさそうです。
そこで登場する強い味方が COALESCE 関数です。
サンプルデータ
CREATE TABLE Staging
(col1 INTEGER,
col2 INTEGER,
col3 INTEGER,
col4 INTEGER,
col5 INTEGER,
col6 INTEGER,
col7 INTEGER,
col8 INTEGER,
col9 INTEGER,
col10 INTEGER);
--オールNULL
INSERT INTO Staging VALUES(NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
--オール1
INSERT INTO Staging VALUES(1, 1, 1, 1, 1, 1, 1, 1, 1, 1);
--少なくとも一つは9
INSERT INTO Staging VALUES(NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, 9);
INSERT INTO Staging VALUES(NULL, NULL, NULL, NULL, NULL, NULL, 0, 1, 9, 9);
ここでは、答え3のコードを SELECT に変更したものを載せましょう。
--答え3(SELECTに変更)
SELECT *
FROM Staging
WHERE COALESCE(col1 ,col2 ,col3 ,col4 ,col5 ,col6 ,col7 ,col8 ,col9 ,col10) IS NULL;
col1 col2 col3 col4 col5 col6 col7 col8 col9 col10
---- ---- ---- ---- ---- ---- ---- ----- ---- ----
NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL
COALESCE は、引数を左から順に走査して、最初の NULL でない値を返すのでした。戻り値が NULL になるのは引数が全て NULL だった場合のみです。
じゃあ、私からも一つ類題を出しましょう。スタンジ君の求めたい行は「オールNULL」でした。では、「オール1」の行を求めるにはどうすればいいでしょう? もちろん、AND でひたすら条件を連結するなんてダサいのはなしです。ほとんど同じような考え方で次のようにすることが可能です。
--オール1の行を求める
SELECT *
FROM Staging
WHERE 1 = ALL (col1 ,col2 ,col3 ,col4 ,col5 ,col6 ,col7 ,col8 ,col9 ,col10);
col1 col2 col3 col4 col5 col6 col7 col8 col9 col10
---- ---- ---- ---- ---- ---- ---- ----- ---- ----
1 1 1 1 1 1 1 1 1 1
まさに「ALL 1」を SQL に直訳しただけ。この方法なら、1に限らずどんな値でも汎用的に使用可能です。要するにこれは、全称量化の一応用だったわけですね。
では最後にもう一問。今のと反対に、「少なくとも1列は9を含む」行を選択するコードを考えてください。もちろん、OR でつなぐのはご法度。さて、ALL の反対である存在量化を表現するには、どうすればいいんでしたっけ?
(ヒント:答えは2通りあります)
第74問 導出テーブルを減らせ
これは工夫のこらされた良問です。結合というのがいまいちどういう動作をしているのかピンと来ない人、また、結合や集約を多用しているクエリを高速化したい人は是非読んでください。
サンプルデータ
CREATE TABLE Accounts
(acct_nbr INTEGER NOT NULL PRIMARY KEY);
CREATE TABLE Foo
(acct_nbr INTEGER NOT NULL
REFERENCES Accounts(acct_nbr),
foo_qty INTEGER NOT NULL);
CREATE TABLE Bar
(acct_nbr INTEGER NOT NULL
REFERENCES Accounts(acct_nbr),
bar_qty INTEGER NOT NULL);
INSERT INTO Accounts VALUES (1);
INSERT INTO Accounts VALUES (2);
INSERT INTO Accounts VALUES (3);
INSERT INTO Accounts VALUES (4);
INSERT INTO Foo VALUES (1, 10);
INSERT INTO Foo VALUES (2, 20);
INSERT INTO Foo VALUES (2, 40);
INSERT INTO Foo VALUES (3, 80);
INSERT INTO Bar VALUES (2, 160);
INSERT INTO Bar VALUES (3, 320);
INSERT INTO Bar VALUES (3, 640);
INSERT INTO Bar VALUES (3, 1);
この問題で何がやらしいかと言えば、acct_nbr で一意になった結果を求めたいのに対し、この列がそのままでは結合キーとして一意にならない、ということに尽きます。そのために、ディヴィドソン氏から寄せられた最初の解は、Foo と Bar を acct_nbr で集約して一意なビュー(本文中で「導出テーブル」と呼ばれているのはこれ)を作ってから、おもむろに Accounts テーブルと結合しているわけです。この方法は集約が二回も発生してパフォーマンスに悪影響を及ぼします。
しかし、よくテーブル同士の関係を見ると、Accounts と Foo、Accounts と Bar は、それぞれ一対多の関係にあり、これら二つのテーブルを結合することだけを考えれば、集約前のテーブルを結合すし、その後に集約することによって結果を acct_nbr で一意にできます。その観点から片方のテーブル(Foo)を集約前に結合したのが、答え2です。ただ、この答え2も、実はまだ無駄があって、「(SELECT * FROM Foo) AS F」というのは端的に「Foo AS F」と同じです。以下にはこの修正も施したコードを載せます。
SELECT A.acct_nbr,
COALESCE(SUM(F.foo_qty), 0) AS foo_qty_tot,
COALESCE(MAX(B.bar_qty), 0) AS bar_qty_tot
FROM Accounts A
LEFT OUTER JOIN Foo F
ON A.acct_nbr = F.acct_nbr
LEFT OUTER JOIN
(SELECT acct_nbr, SUM(bar_qty) AS bar_qty
FROM Bar
GROUP BY acct_nbr) B
ON A.acct_nbr = B.acct_nbr
GROUP BY A.acct_nbr;
acct_nbr foo_qty_tot bar_qty_tot
-------- ----------- -----------
1 10 0
2 60 160
3 80 961
4 0 0
これで一つ中間ビューを減らせました。あとは、もう一つの中間ビューである「B」をなくすことです。これを実現したのが答え3になります。
第75問 もう一軒行こう
座標データをテーブル化するという問題ですね。本書でも64.ボックスで既に3次元の座標まで扱っていますが、そのときは、次元ごとにレコードを分割しました。いわば「次元を行持ち」にする設計だったわけです。今度は、「次元を列持ち」にしたテーブルです。ある意味、こっちのが普通のモデルかも。
サンプルデータ
CREATE TABLE PubMap
(pub_id CHAR(5) NOT NULL PRIMARY KEY,
x INTEGER NOT NULL,
y INTEGER NOT NULL);
--始点(0, 0)
INSERT INTO PubMap VALUES(1, 0, 0);
--半径1:○
INSERT INTO PubMap VALUES(2, 0, 1);
INSERT INTO PubMap VALUES(3, 1, 0);
--半径√2:×
INSERT INTO PubMap VALUES(4, 1, 1);
--半径√5:×
INSERT INTO PubMap VALUES(5, -2, 0);
始点、つまり今いる居酒屋を(0, 0)として、距離 1 以内の居酒屋を探しましょう。円近傍モデルを使う答え1と2を使えば、求める結果は、2 と 3 になります。図示すると次のようなイメージです。
円近傍モデルで居酒屋検索
半径1の円内に含まれる居酒屋が候補として結果に返されます。これは非常に厳密に距離を算出するモデルです。地図を細かい正方形のブロックに分ける平方近傍のモデルだと、もっと大雑把になります。
作成者:ミック
作成日:2007/10/24
最終更新日:2008/02/07

この作品は、クリエイティブ・コモンズ・ライセンスの下でライセンスされています。

